Transformation des features Mapillary avec dbt#
 Date de publication initiale : 5 juin 2025
Date de publication initiale : 5 juin 2025

Salut everybody, tout le monde ! Ça y est, c'est le deuxième article !
Dans le précédent opus, nous avons vu comment Apache Airflow nous permet d'extraire et de charger les features de Mapillary à proximité du réseau routier départemental gardois.
Cette fois, nous allons transformer les données pour les rendre exploitables avec QGIS car, souviens-toi, nous avions stocké directement les éléments retournés par les API au format JSON.
Pour faire ces transformations, nous allons utiliser Data Build Tool : dbt pour les intimes.
dbt#

dbt est un outil de transformation, et uniquement de transformation, de données. En d'autres termes, il est incapable de faire de l'extraction et du chargement et s'attend à ce que les données à transformer soit déjà dans l'entrepôt sous leur forme brute.
Il existe en version Core Open Source ou en version Cloud avec abonnement. Dans sa version Open Source dbt n'est rien de plus qu'un outil en mode CLI (Command Line Interface).
Tout comme Apache Airflow, dbt adopte l'approche "as code" et mélange SQL, Jinja et YAML. Il va donc te falloir réviser tes select, from et where. Cela dit, peut-on vraiment faire l'impasse sur le SQL quand on fait de la data, qu'elle soit géographique ou non ? Je ne pense pas  .
.
Si plusieurs ETL proposent des transformers qui fonctionnent indépendamment du moteur de bases de données cible, dbt lui s'appuie pleinement sur ce dernier en exploitant les fonctions qu'il propose. De fait, toute la puissance du moteur est là, entre tes mains. Avoue que c'est vraiment un plus quand on dispose d'un système extensible tel que PostgreSQL pour, au hasard, traiter des données géographiques avec PostGIS.
Tu es sceptique, je l'étais aussi ! Histoire d'accroître un peu plus tes doutes, je dois t'apprendre que pour faire les transformations, tu auras uniquement droit à des select ; ni ìnsert ni update et encore moins de create ou d'alter puisque c'est dbt qui prend en charge la partie DDL (Data Definition Language).
Difficile, impossible même, pour moi de faire de toi un expert dbt en seulement quelques lignes. Voyons quand-même les notions essentielles et si tu souhaites aller plus loin, je te conseille, comme Satya a déjà pu le faire dans son article, de visionner la playlist dbt de Michael Kahan.
Annonce de la version beta publique de dbt Fusion
Fin mai, dbt Labs a annoncé la publication en version beta de dbt Fusion. Il s'agit d'une réécriture complète du moteur en Rust. Celui-ci apporterait un gain significatif de performances.
Point important, dbt Fusion sera sous licence Elastic Version 2. La société annonce cependant qu'elle continue de maintenir dbt Core sous licence Apache 2.
À ce stade, la beta de dbt Fusion a encore plusieurs limitations et supporte uniquement Snowflake.
Affaire à suivre donc, mais on peut s'attendre à ce que tôt ou tard le développement de dbt Core soit stoppé au profit de dbt Fusion.
Sources#
Pour pouvoir faire les transformations, dbt a besoin de savoir où se trouvent les sources de données dans l'entrepôt. Concrètement, dans le cas de PostgreSQL, cela revient à lui indiquer les schémas et les tables à interroger.
La déclaration des sources se fait via un fichier YAML.
version: 2
sources:
- name: src_hubeau_eaufrance_fr
tables:
- name: stations
tags:
- monthly
- name: observations_tr
tags:
- every_10min
Par défaut en PostgreSQL, le nom de la source correspond au nom du schéma, mais il est également possible de préciser le schéma via la clé schema.
Models#
Un modèle est la description d'une transformation à faire.
Il est construit avec un couple SQL+Jinja / YAML :
- Le SQL+Jinja va porter la requête
selectde transformation des données. - Le YAML va quant à lui donner les informations utiles à dbt pour générer la partie DDL en précisant par exemple le schéma et le nom de la table ou de la vue de stockage.
En aucun cas, le SQL ne doit accéder directement à une table ou une vue de l'entrepôt. Les from doivent à la place faire référence à une source, via le template Jinja {{ source("<source_name>", "<table_name>") }}, ou à un autre modèle, via le template Jinja {{ ref("<model_name>") }}.
Voici par exemple un modèle de transformation des observations extraites et chargées dans l'entrepôt depuis l'API Hydrométrie de Hubeau.
Son rôle est de transformer le résultat JSON issu de l'appel à l'API en un tableau des observations contenant 4 colonnes : code_station, date_heure, resultat et grandeur_hydro.
version: 2
models:
- name: stg_hubeau_eaufrance_fr__observations
config:
alias: observations
schema: stg_hubeau_eaufrance_fr
with observations as (
select *
from {{ source("src_hubeau_eaufrance_fr", "observations_tr")}}
),
details_observations as (
select
observations.code_station,
details_observation
from observations
cross join jsonb_array_elements(observations -> 'data') as details_observation
),
selections_typages_renommages as (
select
code_station,
{{ to_utc_timestamp_or_null("details_observation ->> 'date_obs'", '^\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}Z$', 'YYYY-MM-DD"T"HH24:MI:SS"Z"') }} as date_heure,
(details_observation ->> 'resultat_obs')::numeric as resultat,
details_observation ->> 'grandeur_hydro' as grandeur_hydro
from details_observations
)
select *
from selections_typages_renommages
Macros#
Lorsqu'on souhaite factoriser du code, il est d'usage en bases de données de créer des procédures stockées. Avec dbt, on utilisera plutôt des macros.
Les macros sont des blocs de SQL réutilisables. Par exemple, dans la requête de transformation Hubeau qui précède, tu peux voir un appel à to_utc_timestamp_or_null.
Cette macro, nous l'avons développée pour faciliter les transformations de chaînes de caractères en dates et heures, tout en s'assurant que la conversion n'entraîne pas une erreur par la validation préalable d'une expression régulière.
{% macro to_utc_timestamp_or_null(column, regexp_check, format) %}
case when {{ column }} ~ '{{ regexp_check }}' then to_timestamp({{ column }}, '{{ format }}')::timestamp at time zone 'UTC' end
{% endmacro %}
Architecture en médaillon#
L'architecture en médaillon n'est pas propre à dbt. Il s'agit d'un modèle de structuration des données en 3 couches :
- La couche Bronze : elle correspond aux données non transformées telles qu'extraites depuis leur source.
- La couche Silver : dans cette couche, les données sont nettoyées, validées et transformées. Il peut notamment être question de normalisation et d'enrichissement via le croisement et l'association de données provenant de sources distinctes.
- La couche Gold : elle contient les données hautement transformées et agrégées, prêtes pour l'analyse et la consommation par les utilisateurs finaux. Les données sont en général dénormalisées pour en faciliter l'analyse ; modèles en étoile ou "one big table".
L'objectif est de garantir l’atomicité et la cohérence des traitements en isolant les différentes étapes de transformation dans des couches spécifiques.
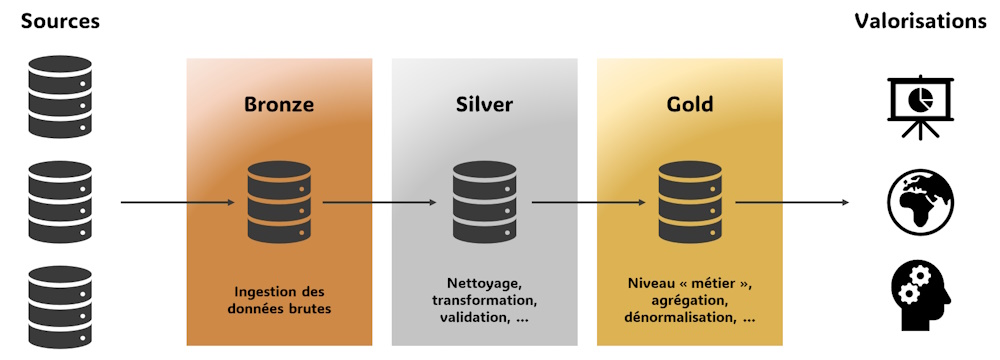
Cette approche présente des similitudes avec l'architecture logicielle en 3 couches où chaque strate (et même chaque classe en programmation orientée objet) a une responsabilité unique ; la couche d'accès aux données, la couche métier et la couche de présentation.
Matérialisation#
La matérialisation détermine la façon dont dbt stocke le résultat des transformations, c'est à dire le résultat d'exécution des modèles, dans l'entrepôt.
Concrètement, et dans la mesure où dbt se charge du DDL, il est question de lui dire s'il doit créer une table ou une vue dans la base de données.
En règle générale, les modèles sont organisés en couches suivant l'architecture en médaillon. Le mode de matérialisation est alors fixé au niveau du projet, dans le fichier dbt_project.yml, pour l'ensemble des modèles d'une même couche.
models:
taradata:
2_staging:
+materialized: view
3_warehouses:
+materialized: table
4_marts:
+materialized: table
Il reste possible de redéfinir cette matérialisation par défaut sur un modèle spécifique grâce à la clé materialized de la section config du YAML.
Modèles incrémentaux#
Lorsque les matérialisations table ou view sont retenues, dbt va recréer à chaque lancement la structure de données, et donc, exécuter l'ordre create table as select... ou create view as select... correspondant.
Cette approche a plusieurs avantages. D'une part, elle est résiliente car la suppression malencontreuse de la structure peut être corrigée en rejouant le modèle. Par ailleurs, comme toutes les données sont retraitées, il n'est pas utile d'identifier de façon chirurgicale les lignes ayant évoluées, ce qui rend la rédaction du modèle de transformation simple.
Cependant, les matérialisations table et view trouvent leurs limites quand le volume de données est important ou lorsque le but est de conserver l'historique des données alors même que la source ne le propose pas.
dbt propose pour cela le mode incremental. Avec lui, une table est créée à la première exécution du modèle. Les exécutions suivantes se chargent ensuite de mettre à jour et/ou d'insérer les nouvelles données en fonction du paramétrage défini pour le modèle.
Lignage et parallélisation#
C'est probablement le point fort de dbt ; sa capacité à déterminer le lignage des modèles.
Imagine, tu récupères le tout dernier millésime de la BD TOPO® et tu dois reconstruire toutes les données qui dépendent du thème commune. "Quels sont les processus que je dois relancer ? Est-ce que je dois faire celui-là avant celui-ci ? Peut-être que je peux lancer ces deux transformations en même temps pour aller plus vite, mais peut-être pas.". Bref, la galère !
Avec dbt, plus besoin de se faire des nœuds au cerveau grâce au graphe de dépendances des modèles.
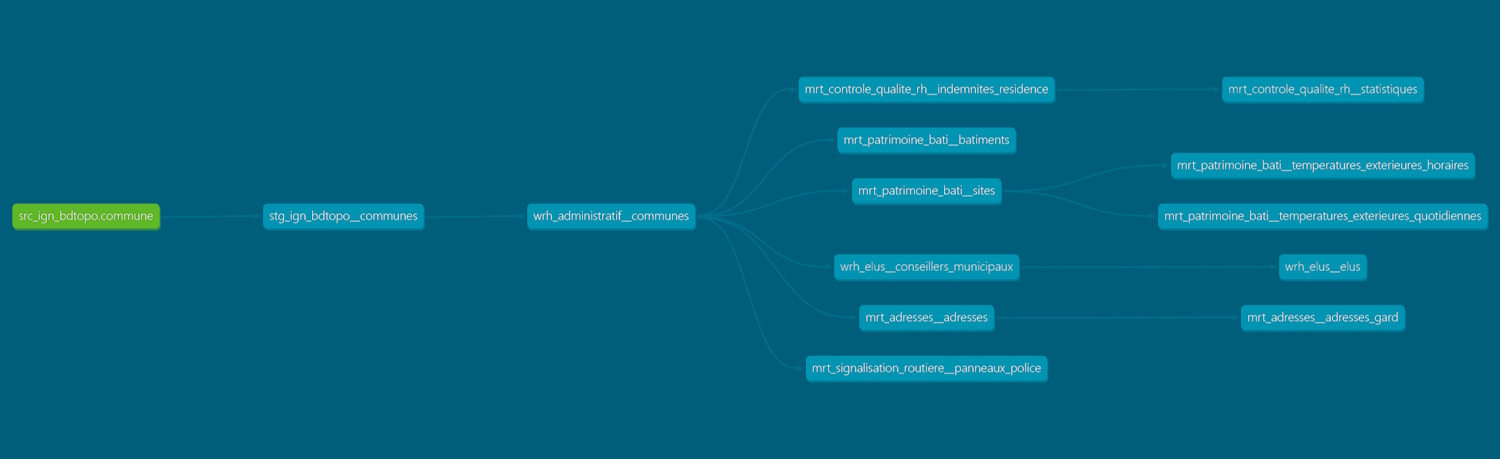
Cette fonctionnalité ne se limite pas à un rendu graphique. Il est aussi possible de demander la reconstruction des descendants d'une source ou d'un modèle en suffixant celui-ci d'un +, comme par exemple dans la commande suivante :
dbt run --select source:src_ign_bdtopo.commune+
Ce lignage permet non seulement à dbt de savoir l'ordre dans lequel il doit faire les transformations, mais il est aussi capable d'identifier les modèles indépendants et de les exécuter en parallèle.
Documentation des modèles#
C'est un autre avantage de dbt ; il est possible de documenter, en markdown, les modèles depuis le fichier YAML. Cette possibilité concerne aussi bien le modèle lui-même que les colonnes qui le constituent.
- name: wrh_hydrometrie__stations
description: >
Les stations hydrométriques du Gard et de ses départements limitrophes.
Les données sont issues de [hubeau.eaufrance.fr](https://hubeau.eaufrance.fr/) et [vigicrues.gouv.fr](https://www.vigicrues.gouv.fr/).
config:
alias: stations
schema: wrh_hydrometrie
indexes:
- columns: ["code_station"]
unique: True
- columns: ["code_troncon"]
- columns: ["geom"]
type: "gist"
columns:
- name: code_station
description: "Le code de la station."
- name: code_troncon
description: "Le code du tronçon."
- name: libelle
description: "Le libellé de la station."
- name: libelle_site
description: "Le libellé du site."
- name: type
description: "Le type de la station (HC, DEB, LIMNI, LIMNIMERE, LIMNIFILLE)."
- name: en_service
description: "Détermine si la station est en service ou non."
- name: geom
description: "La localisation ponctuelle de la station."
Cette documentation est ensuite visualisable au travers d'une page Web que dbt peut générer grâce à la commande dbt docs generate.
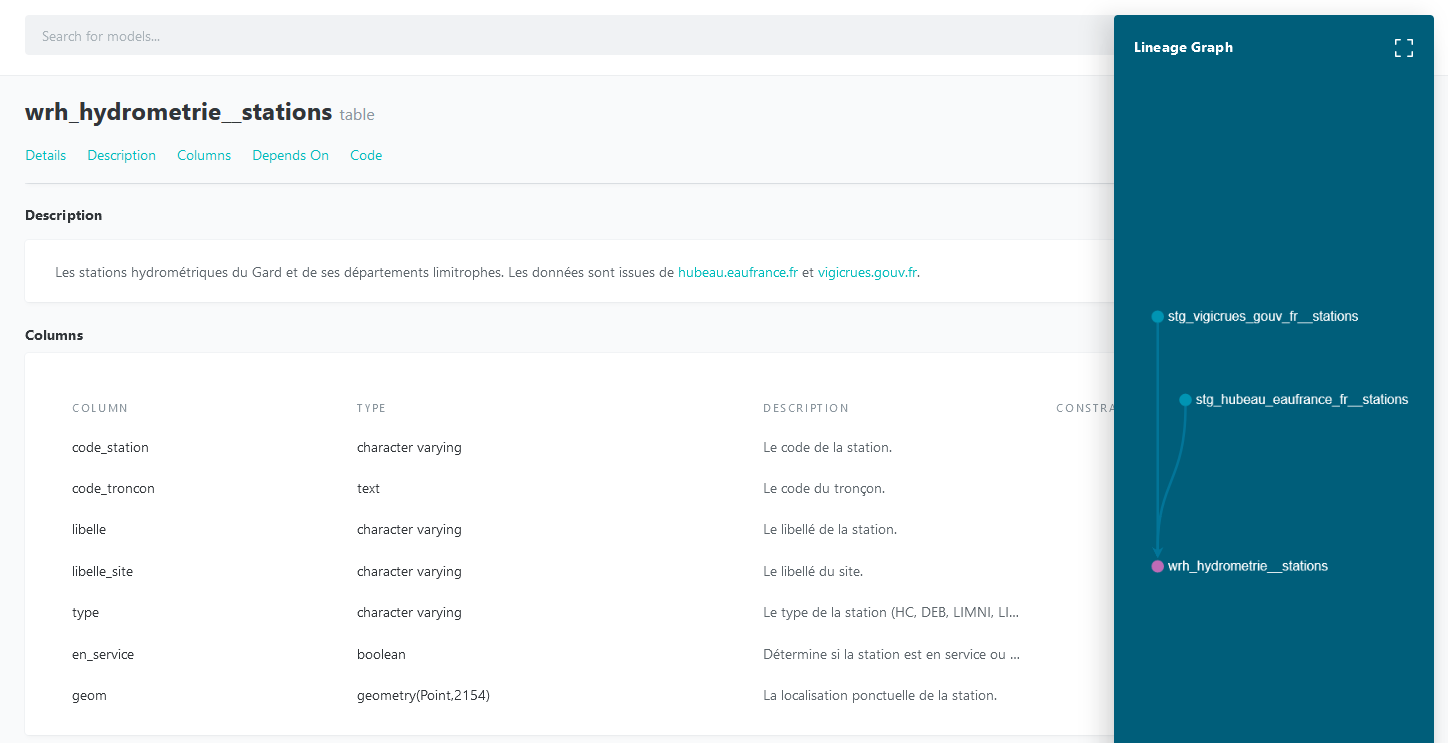
Il est également possible de demander à dbt de persister la documentation dans les commentaires des tables, vues et colonnes PostgreSQL. Ainsi, la description est directement visualisable dans QGIS.
Transformation des features#
Voyons maintenant comment dbt nous permet de transformer les features de Mapillary, de leur forme brute JSON à une couche utilisable dans QGIS.
D'abord, les best-practices#
La structuration de notre projet dbt est largement inspirée des préconisations de l'éditeur consultables dans son guide des bonnes pratiques.
Les transformations vont se faire en trois étapes ; staging > intermediate > marts. Je vais essayer de t'expliquer celles-ci en gardant pour image celle de la grande distribution.
Nous sommes les gestionnaires du super-data-marché de Nîmes, le spécialiste de la data à prix discount.
Nous nous fournissons auprès de dizaines de partenaires. Chacun nous met à disposition le catalogue de ses références.
S'il est indéniable qu'un effort de mise en avant des produits a été fait par chaque fournisseur, nous faisons face à plusieurs difficultés.
En effet, certains de nos fournisseurs sont basés à Barcelone et le catalogue qu'ils nous présentent est en espagnol. Nous avons également un partenaire à Hastings au Sud-Est de Londres. Non seulement son catalogue est en anglais mais en plus les prix sont exprimés en livre sterling. Et je ne te parle même pas des unités de mesures...
- Staging ; Un pré-traitement de l'ensemble des catalogues est fait ; même langue, mêmes unités et prix en €uros. A cette étape, chaque catalogue est analysé indépendamment des autres, le but étant d'uniformiser.
- Intermediate ; Nous pouvons maintenant commander les produits auprès de nos partenaires. L'objectif est d'alimenter nos entrepôts. Dès la livraison, un tri est fait de sorte à ce que les produits de notre stock soient classés non pas par fournisseur, mais par gamme.
- Marts ; Les produits sont sortis du stock et mis en rayon. Les prix au kilo et prix au litre sont calculés et nous mettons en avant les informations utiles concernant les articles, telles que la provenance et les allergènes. En bref, tout est fait pour satisfaire le client et l'aider dans ses décisions d'achat.
Source#
Avant toute chose, nous devons indiquer à dbt où se trouvent les données brutes grâce au fichier YAML suivant.
version: 2
sources:
- name: src_mapillary_com
tags:
- monthly
tables:
- name: features
C'est là que se trouve le résultat de notre dur labeur d'extraction et de chargement des features vu lors du précédent article.
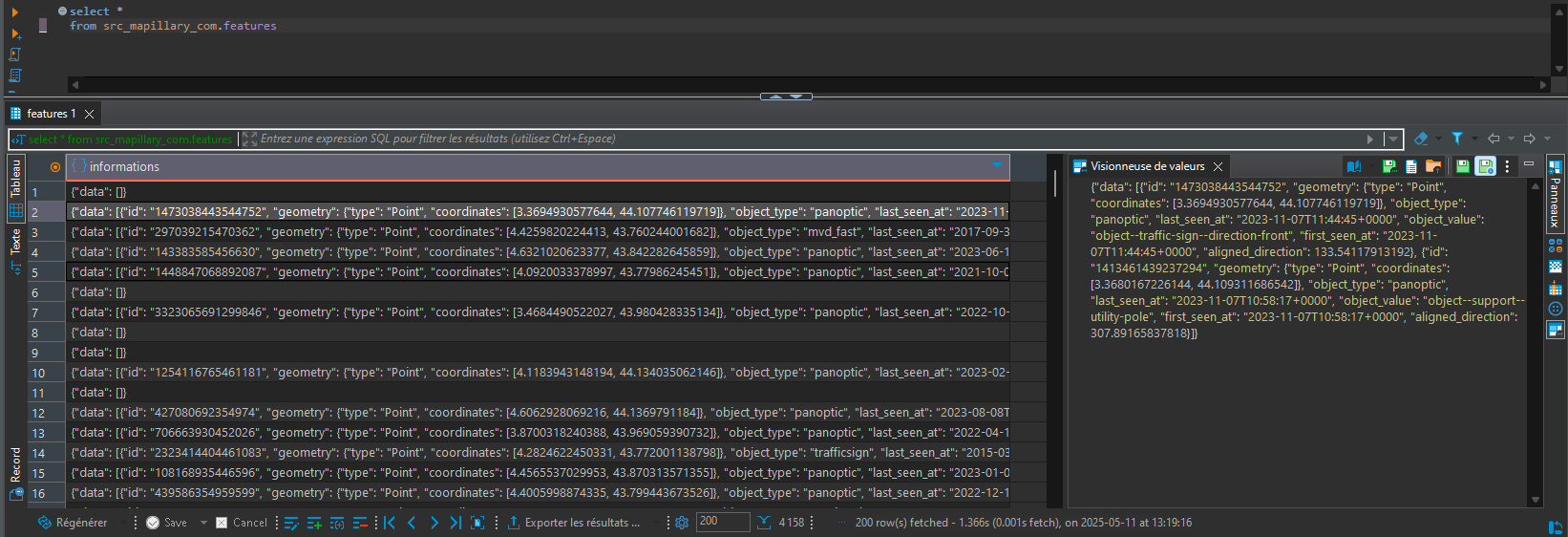
Il est possible d'associer aux sources des tags comme tu peux le voir dans le YAML. Ceux-ci n'ont pas d'incidence directe sur dbt. Ils peuvent cependant être utilisés comme critère de lancement des modèles. Par exemple, le tag monthly nous permet d'exécuter les modèles dépendants d'une source mise à jour de façon mensuelle via la commande :
dbt run --select tag:monthly+
Staging#
L'objectif du staging est de rendre les données sources prêtes à l'emploi. Il n'est pas question ici de commencer les croisements (jointures, unions, ...) avec d'autres données.
Comme dans notre exemple des catalogues de produits, nous allons dans cette étape "traduire" les données extraites et chargées depuis Mapillary. Par traduction, on entend convertir en lignes et colonnes le champs jsonb. Par ailleurs, nous conservons à cette étape le lien avec le fournisseur des données mais nous avons fait le choix d'utiliser le français pour notre entrepôt.
Ainsi, le fichier YAML suivant précise que le résultat d'exécution du modèle doit être stocké dans la vue elements (matérialisation définie au niveau du projet) du schéma stg_mapillary_com.
version: 2
models:
- name: stg_mapillary_com__elements
config:
alias: elements
schema: stg_mapillary_com
Le fichier SQL quant à lui détermine comment le jsonb est transformé.
with features as (
select *
from {{ source("src_mapillary_com", "features") }}
),
selections_typages_renommages as (
select
distinct
(feature ->> 'id')::bigint as id_element,
(feature ->> 'first_seen_at')::timestamp as date_heure_premiere_detection,
(feature ->> 'last_seen_at')::timestamp as date_heure_derniere_detection,
feature ->> 'object_type' as type,
string_to_array(feature ->> 'object_value', '--') as valeur,
(feature ->> 'aligned_direction')::numeric as alignement,
(feature -> 'geometry' -> 'coordinates' ->> 0)::numeric as longitude,
(feature -> 'geometry' -> 'coordinates' ->> 1)::numeric as latitude
from features
cross join jsonb_array_elements(informations -> 'data') feature
),
geolocalisations as (
select
*,
case
when {{ is_valid_longitude("longitude") }} and {{ is_valid_latitude("latitude") }}
then {{ to_srid_2154(make_2d_point_4326("longitude", "latitude")) }}
end as geom
from selections_typages_renommages
)
select *
from geolocalisations
Tu peux voir que la requête s'appuie aussi bien sur des opérateurs et fonctions propres à PostgreSQL (->>, jsonb_array_elements) que sur des macros développées pas nos soins. Voici par exemple le code de la macro make_2d_point_4326.
{% macro make_2d_point_2154(x, y) %}
ST_SetSRID(ST_MakePoint({{ x }}, {{ y }}), 2154)
{% endmacro %}
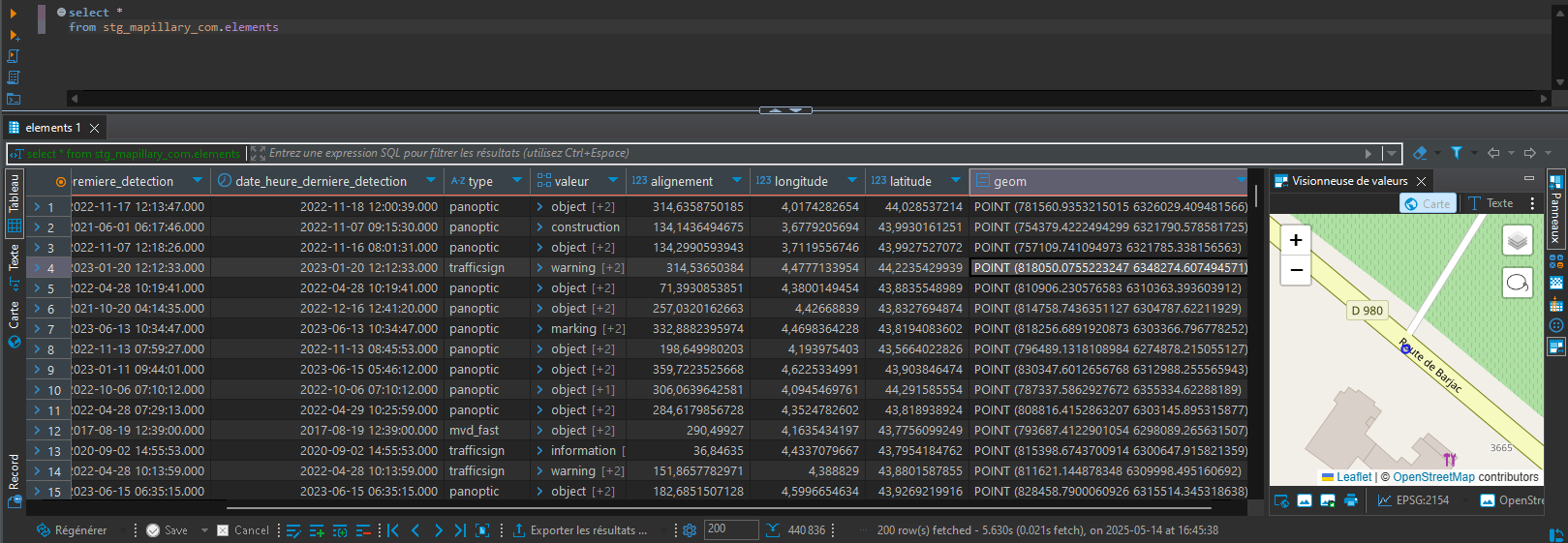
Après exécution du modèle, la vue est disponible et requêtable dans l'entrepôt.
Intermediate (ou Warehouses)#
La phase intermédiaire (que nous avons décidé d'appeler warehouses puisqu'il est question d'organiser le stock de données) est selon moi l'étape primordiale. C'est grâce à elle que tu vas t'approprier les données collectées et façonner le modèle de données qui te permettra, à l'étape suivante, de répondre aux besoins de tes utilisateurs.
Si lors du staging, chaque source est analysée indépendamment des autres, il va être question ici de les combiner, de les comparer, de les restructurer, de les filtrer ; bref de faire des multiples sources un ensemble cohérent de données.
Pour prendre un exemple, si nous collectons des données depuis Hubeau et Vigicrues, ces deux sources ne font plus qu'une après le passage en warehouses pour nous fournir des informations à propos de l'état des cours d'eau dans le Gard.
Dans notre cas, nous essayons à cette étape de nous rapprocher d'un modèle relationnel normalisé, même s'il faut bien avouer que nous nous autorisons quelques écarts. Concernant les features Mapillary, nous allons profiter de cette étape pour :
- isoler les panneaux de police de circulation,
- affiner les noms des colonnes et traduire leur contenu,
- ne conserver que les panneaux à moins de 10 mètres d'une route départementale.
Sur ce dernier point, nous avions pris soin lors de l'EL de ne conserver que les cellules à proximité du réseau. Malgré tout, chacune couvre environ 90 hectares et une partie seulement de cette surface peut se trouver réellement à 10 mètres d'une route.
Tu peux voir dans le YAML que, si nous mentionnons Mapillary dans la documentation, le schéma comme la table portent désormais un nom "métier" (wrh_signalisation_routiere.panneaux_police).
version: 2
models:
- name: wrh_signalisation_routiere__panneaux_police
description: >
Les panneaux de police de circulation à proximité (<= 10 mètres) des routes départementales présentes dans le référentiel routier.
Les données sont issues de [Mapillary](https://www.mapillary.com).
Pour plus d'informations, voir la [documentation de Mapillary sur les panneaux de signalisation](https://www.mapillary.com/developer/api-documentation/traffic-signs?locale=fr_FR).
config:
alias: panneaux_police
schema: wrh_signalisation_routiere
indexes:
- columns: ["categorie"]
- columns: ["nom"]
- columns: ['geom']
type: 'gist'
columns:
- name: id_panneau_police
description: "L'identifiant du panneau de police de circulation."
- name: date_heure_premiere_detection
description: "La date et l'heure de première détection du panneau."
- name: date_heure_derniere_detection
description: "La date et l'heure de dernière détection du panneau."
- name: categorie
description: "La catégorie du panneau selon Mapillary (ex : réglementaire, danger)."
- name: nom
description: "Le nom du panneau selon Mapillary."
- name: aspect
description: "L'aspect du panneau selon Mapillary."
- name: alignement
description: "L'alignement du panneau."
- name: geom
description: "La localisation ponctuelle du panneau."
Dans le SQL, l'appel à ST_DWithin nous permet d'ignorer les éléments à plus de 10 mètres des tronçons du référentiel routier.
with elements as (
select *
from {{ ref("stg_mapillary_com__elements") }}
),
noms_panneaux as (
select *
from {{ ref("stg_mapillary_com__noms_panneaux") }}
),
troncons as (
select *
from {{ ref("wrh_referentiel_routier__troncons") }}
),
jointures_selections as (
select
e.id_element as id_panneau_police,
e.date_heure_premiere_detection,
e.date_heure_derniere_detection,
case e.valeur[1]
when 'complementary' then 'complémentaire'
when 'general' then 'général'
when 'information' then 'information'
when 'regulatory' then 'réglementaire'
when 'warning' then 'danger'
else e.valeur[1]
end as categorie,
coalesce(np.nom_fr, e.valeur[2]) as nom,
e.valeur[3] as aspect,
e.alignement,
e.geom
from elements e
left join noms_panneaux np on np.valeur = e.valeur[2]
where e.type = 'trafficsign'
and exists (
select *
from troncons t
where not t.fictif
and ST_DWithin(t.geom, e.geom, 10)
)
)
select *
from jointures_selections
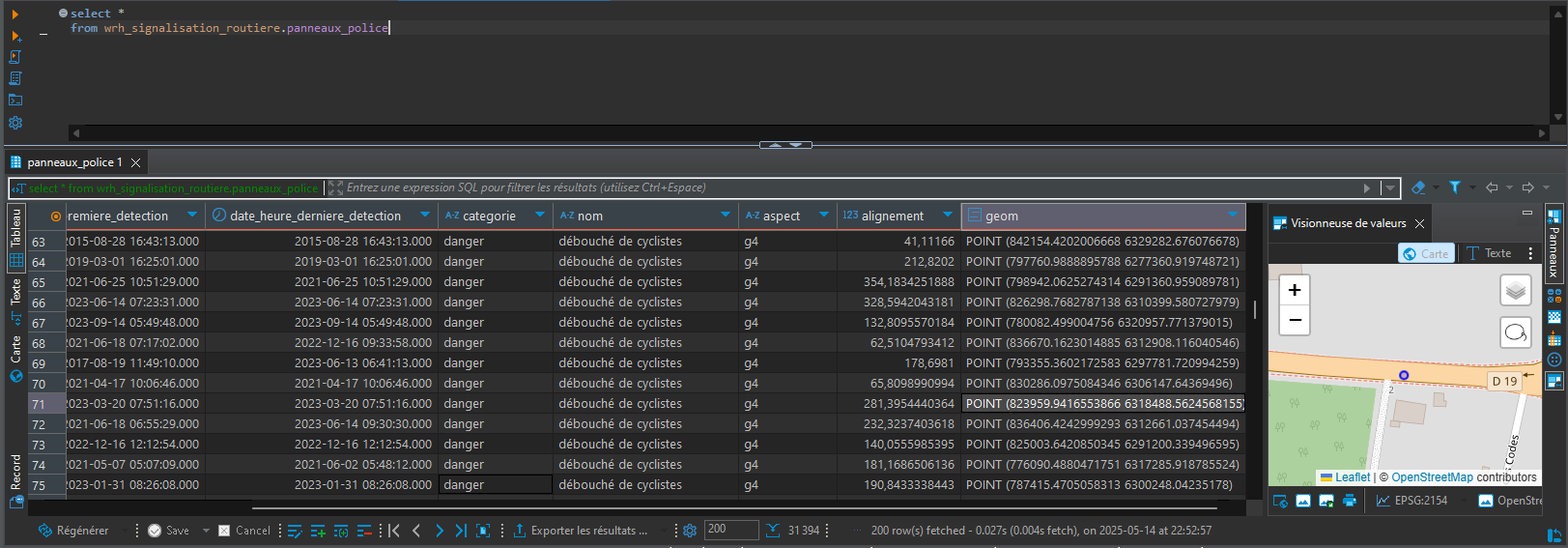
L'exécution du modèle aboutit à la création de la table dans l'entrepôt.
Marts#
Last but not least, les marts !
L'objectif est simple, rendre la vie de tes utilisateurs plus simple et plus belle  . Comment fait-on ça ? Il y a plusieurs pistes.
. Comment fait-on ça ? Il y a plusieurs pistes.
Tu peux commencer par mettre à plat les données, autrement dit, dénormaliser ton modèle. Imagine, tu as un modèle relationnel communes -> départements -> régions, et bien tu peux mettre l'ensemble des informations dans une même table pour éviter à ton utilisateur de devoir faire les jointures.
Tu as probablement déjà entendu dire que la règle est de ne pas stocker les champs calculés en base de données ! Et bien il est temps pour toi d'enfreindre les règles. C'est un exemple un peu simpliste mais si tu as la date de début et la date de fin dans ton outil de suivi d'activités, alors tu peux calculer la durée de la tâche. Ton utilisateur pourra ainsi plus facilement identifier les activités de ces 3 derniers mois qui ont demandé plus de 2h.
Et surtout, dans le cas d'une analyse orientée décisionnel, c'est le bon moment pour faire tes agrégats. Par exemple, tu pourras faire la somme de tes recettes et de tes dépenses par mois. Non seulement, cela facilitera le travail d'analyse de ton utilisateur qui aura accès aux chiffres consolidés, mais en plus ce sera plus rapide pour lui car déjà pré-calculé, surtout s'il est question de traiter de gros volumes.
Pour le cas d'usage Mapillary, nous ne sommes clairement pas sur du décisionnel. L'idée est de mettre à disposition de l'utilisateur une couche géographique. Celle-ci sera agrémentée de nouveaux champs, par rapport au warehouse, qui devraient en faciliter l'exploitation.
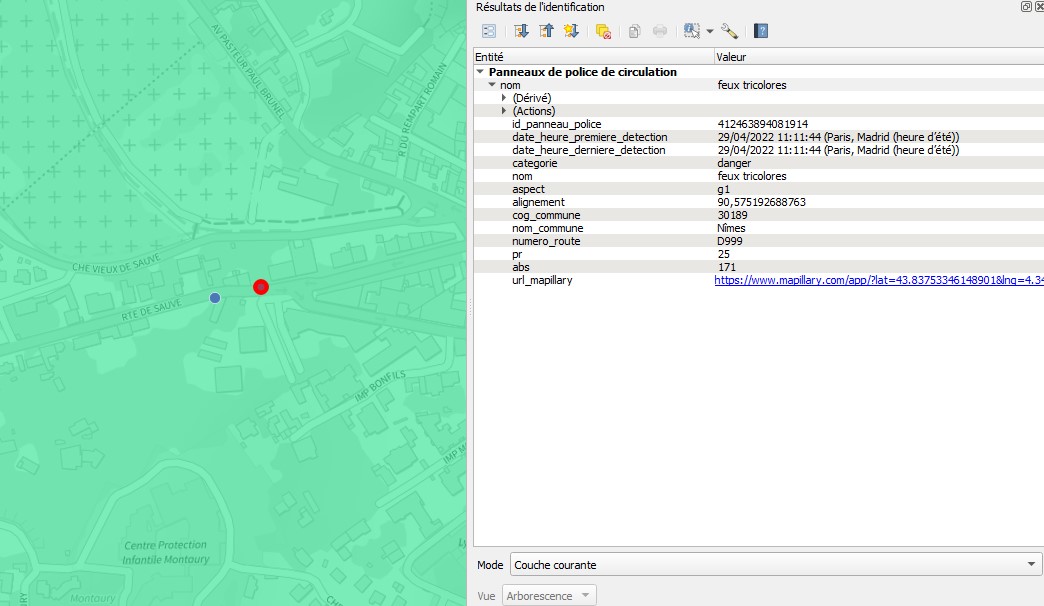
D'une part, avec la localisation du panneau, nous allons déterminer la commune sur laquelle il est implanté. Nous allons aussi indiquer à proximité de quelle route départementale il se trouve et donner sa localisation en PR+Abscisse. Enfin, nous allons proposer à l'utilisateur l'URL d'accès directe au droit du panneau dans Mapillary. Il pourra alors visualiser les images ayant permis la détection et confirmer qu'il s'agit du bon panneau.
Tout ceci est fait à l'aide de la requête suivante.
with panneaux_police as (
select *
from {{ ref("wrh_signalisation_routiere__panneaux_police") }}
),
communes as (
select *
from {{ ref("wrh_administratif__communes") }}
),
jointures_selections as (
select
pp.id_panneau_police,
pp.date_heure_premiere_detection,
pp.date_heure_derniere_detection,
pp.categorie,
pp.nom,
pp.aspect,
pp.alignement,
c.cog_commune,
c.nom as nom_commune,
pra.numero_route,
pra.pr_abs / 10000 as pr,
pra.pr_abs % 10000 as abs,
concat({{ point_to_mapillary("pp.geom", 20) }}, '&trafficSign=all') as url_mapillary,
pp.geom
from panneaux_police pp
inner join communes c on ST_Intersects(pp.geom, c.geom)
cross join lateral ({{ point_vers_pr_abs("pp.geom") }}) pra
)
select *
from jointures_selections
La macro point_to_mapillary est une simple concaténation de chaînes qui exploite la localisation ponctuelle du panneau.
{% macro point_to_mapillary(point, zoom = 15) %}
concat('https://www.mapillary.com/app/?lat=', ST_Y(ST_Transform({{ point }}, 4326)), '&lng=', ST_X(ST_Transform({{ point }}, 4326)), '&z=', {{ zoom }})
{% endmacro %}
Bien entendu, nous mettons à disposition de l'utilisateur la documentation du modèle.
version: 2
models:
- name: mrt_signalisation_routiere__panneaux_police
description: >
Les panneaux de police de circulation à proximité (<= 10 mètres) des routes départementales présentes dans le référentiel routier.
Les données sont issues de [Mapillary](https://www.mapillary.com).
Pour plus d'informations, voir la [documentation de Mapillary sur les panneaux de signalisation](https://www.mapillary.com/developer/api-documentation/traffic-signs?locale=fr_FR).
config:
alias: panneaux_police
schema: mrt_signalisation_routiere
indexes:
- columns: ['geom']
type: 'gist'
columns:
- name: id_panneau_police
description: "L'identifiant du panneau de police de circulation."
- name: date_heure_premiere_detection
description: "La date et l'heure de première détection du panneau."
- name: date_heure_derniere_detection
description: "La date et l'heure de dernière détection du panneau."
- name: categorie
description: "La catégorie du panneau selon Mapillary (ex : réglementaire, danger)."
- name: nom
description: "Le nom du panneau selon Mapillary."
- name: aspect
description: "L'aspect du panneau selon Mapillary."
- name: alignement
description: "L'alignement du panneau."
- name: cog_commune
description: "Le Code Officiel Géographique de la commune."
- name: nom_commune
description: "Le nom de la commune."
- name: numero_route
description: "Le numéro de la route départementale à proximité."
- name: pr
description: "Le PR de localisation du panneau sur la route départementale."
- name: abs
description: "L'abscisse de localisation du panneau sur la route départementale."
- name: url_mapillary
description: "L'URL d'accès à Mapillary au droit du panneau."
- name: geom
description: "La localisation ponctuelle du panneau."
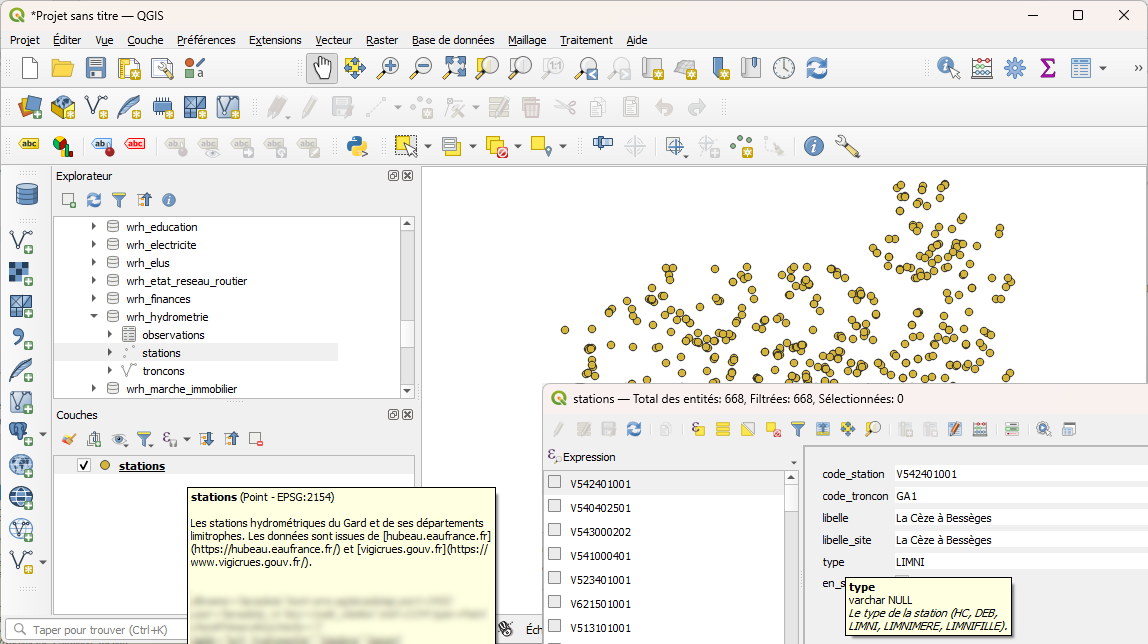
L'exécution du modèle crée la table mrt_signalisation_routiere.panneaux_police qu'il est possible d'afficher dans QGIS.
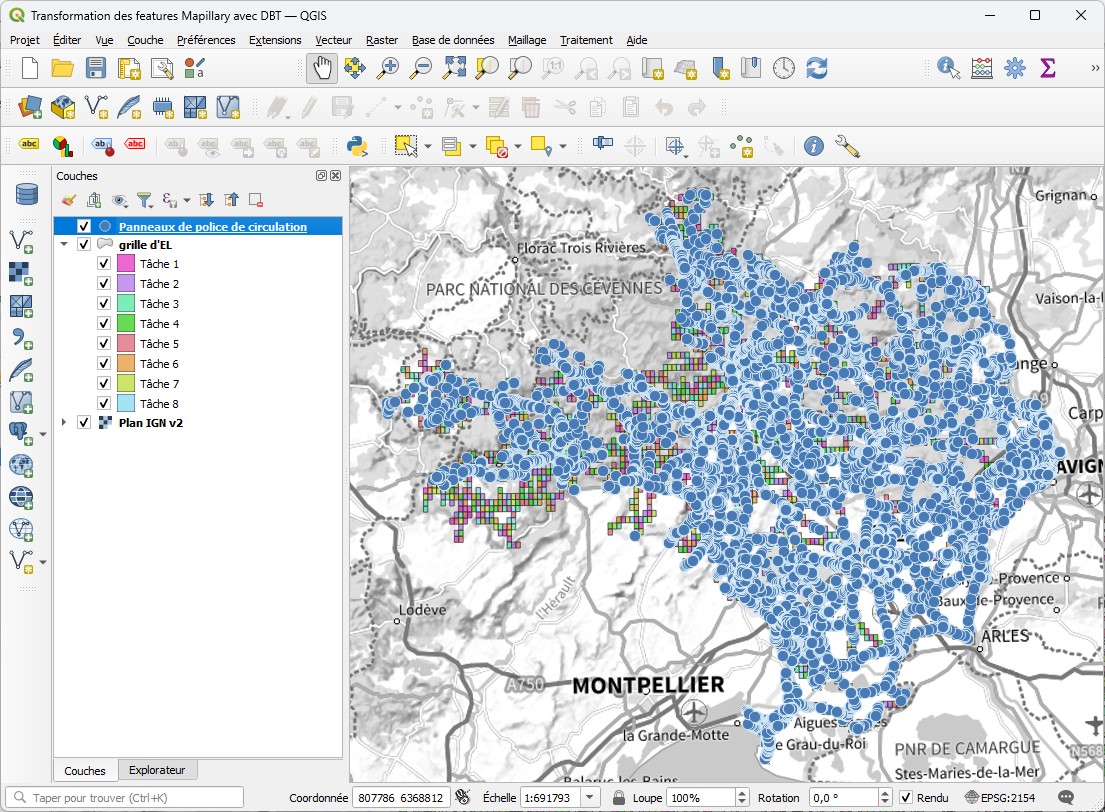
Grâce aux différents champs, l'utilisateur peut filtrer les panneaux annonçant un danger sur la D999 à Nîmes.
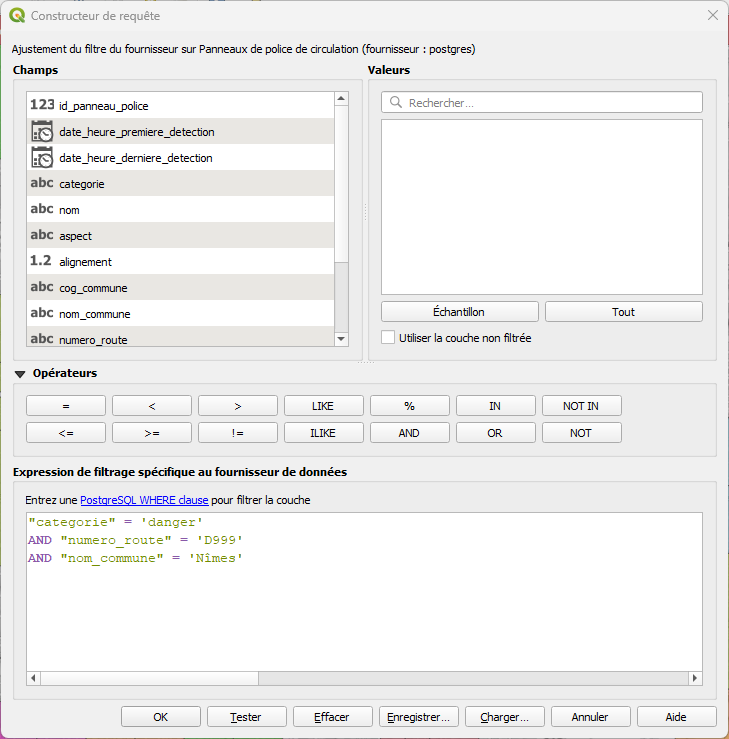
Seuls les panneaux validant les critères s'affichent.
Parmi les attributs, on retrouve l'URL d'accès à Mapillary.
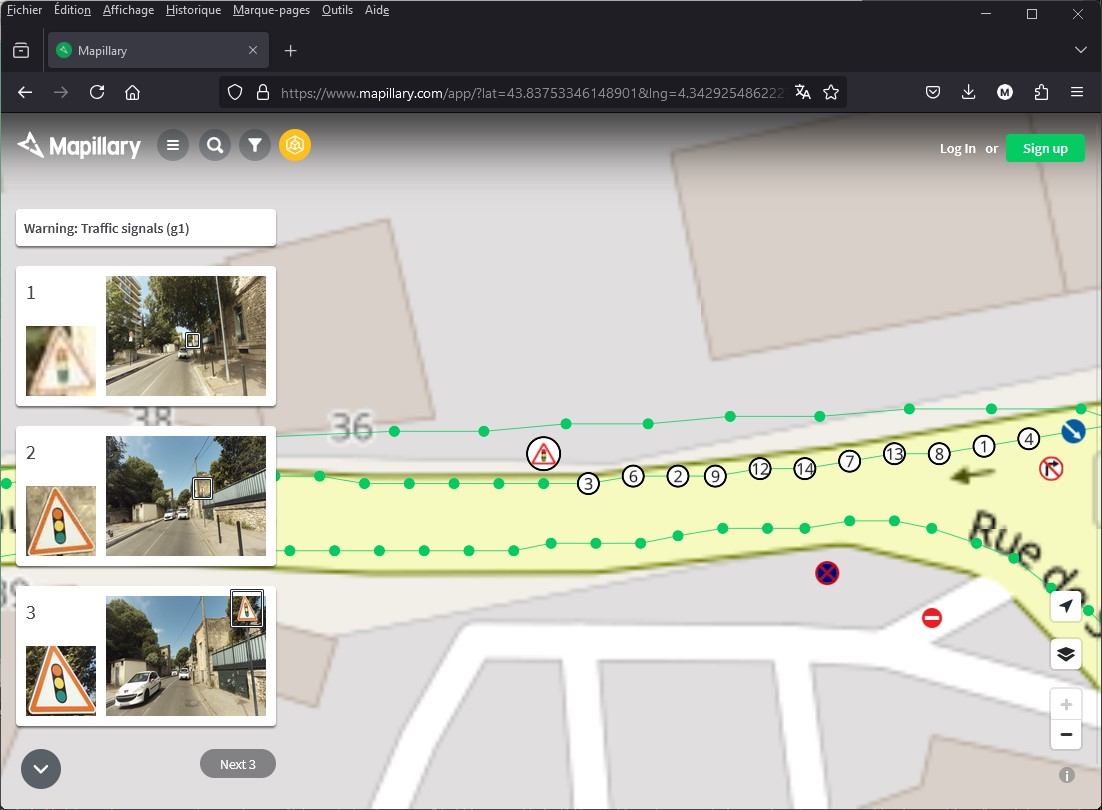
Par un simple clic, l'utilisateur peut naviguer vers Mapillary et afficher les images du panneau.
Conclusion#
Ma conviction est que les métiers de la géomatique et de la data-science vont inévitablement se rapprocher, et possiblement fusionner. D'ailleurs, j'ai déjà pu lire dans certaines signatures e-mails la mention "geodatascientist". Le travail de la géomaticienne/du géomaticien ne se limite plus à la production de cartes. Parallèlement, il parait peu probable qu'un data*ist puisse faire toute une carrière sans jamais traiter de données rattachées à un territoire.
Dès lors, je trouve opportun de regarder et de s'inspirer de ce qu'il se fait dans ces deux mondes ; c'est ainsi que nous avons construit Taradata.
Au travers de ces deux articles (et même trois avec celui de Satya), j'ai souhaité te montrer que les principes que nous avons empruntés à la data-science peuvent s'adapter aux besoins et contraintes de la géomatique. Avec Mapillary comme cas d'usage, nous avons vu comment extraire et charger des données avec Apache Airflow, puis comment les transformer avec dbt pour au final les exploiter dans QGIS. Cependant, j'aurais tout à fait pu te présenter ces outils en illustrant avec des thématiques plus éloignées de la géographie ; les finances ou les RH par exemple.
Je suis conscient que mon propos est dense du fait notamment des nombreuses sections de code qui y apparaissent, que ce soit en Python ou en SQL. Je ne peux pas le nier, la mise en place d'une Modern Data Stack géographique n'est pas triviale. La prise en main des différents outils demande du temps et de l'investissement. Pour autant, notre stack est entièrement basée sur des briques Open Source déployées On Premise. D'une part, cela nous apporte une forme de souveraineté. D'autre part, je suis convaincu que cet investissement sera rapidement rentabilisé. D'ailleurs, par investissement il est surtout question d'acquérir de nouvelles compétences et il me semble qu'on perd rarement son temps quand on apprend.
C'est d'ailleurs ce que tu es venu/e faire sur Geotribu non ? 
Auteur·ice#
Michaël GALIEN#

Diplômé de Polytech'Montpellier, spécialité Informatique & Gestion, je débute ma carrière dans l'édition de logiciels. En qualité d'ingénieur-développement, je travaille sur différents projets en .NET pour le compte d'un éditeur spécialisé en Lecture et Reconnaissance Automatique de Documents (LAD/RAD).
En 2013, j'intègre le département du Gard et commence à utiliser le SIg. Je crois alors que la géomatique consiste à empiler des SHP dans ArcGIS pour faire des cartes. Et puis je découvre PostGIS, l'extension géographique de PostgreSQL avec lequel j'avais déjà travaillé dans le privé.
Après presque 10 ans au sein de la direction en charge du patrimoine routier et bâtimentaire, j'intégre en 2023 la Direction de l'Innovation et des Systèmes d'Information en tant qu'administrateur de la données. Mon rôle est d'y développer Taradata, notre stack de traitement et de valorisation du patrimoine de données départemental.
Taradata est construite suivant les principes d'une Modern Data Stack. Elle est contituée de plusieurs briques dont PostgreSQL/PostGIS, Apache Airflow, GDAL/OGR, DBT, Metabase et QGIS.
Licence #
Ce contenu est sous licence Creative Commons International 4.0 BY, avec attribution et partage dans les mêmes conditions.
Les médias d'illustration sont potentiellement soumis à d'autres conditions d'utilisation.
Réutiliser, citer l'article
Vous êtes autorisé(e) à :
- Partager : copier, distribuer et communiquer le matériel par tous moyens et sous tous formats pour toute utilisation, y compris commerciale
- Adapter : remixer, transformer et créer à partir du matériel pour toute utilisation, y compris commerciale.
L'Offrant ne peut retirer les autorisations concédées par la licence tant que vous appliquez les termes de cette licence.
Citer cet article :
"Transformation des features Mapillary avec dbt" publié par Michaël GALIEN sur Geotribu - Source : https://geotribu.fr/articles/2025/2025-06-05_taradata_transform_mapillary/
Commentaires
Une version minimale de la syntaxe markdown est acceptée pour la mise en forme des commentaires.
Propulsé par Isso.
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


