Extraction et chargement des features Mapillary avec Apache Airflow#
 Date de publication initiale : 27 mai 2025
Date de publication initiale : 27 mai 2025

Salut à toi chère lectrice/cher lecteur ! Dans son article intitulé "L'enjeu de la data au département du Gard", Satya t'explique comment nous avons combiné Modern Data Stack (MDS) et géomatique au sein de notre stack data, qui porte le joli petit nom de Taradata.
Le but : être en mesure de valoriser le patrimoine de données départemental (rien que ça !) et ainsi offrir aux élus, aux directions et aux services, les informations clés pour la prise de décisions et le suivi de leurs actions.
Conformément aux principes de la MDS, Taradata est construite de façon modulaire avec notamment PostgreSQL/PostGIS pour l'entreposage des données, Apache Airflow pour l'orchestration des traitements et DBT pour les transformations.
Les données sont extraites depuis leur source avant d'être chargées dans l'entrepôt pour enfin être transformées. Et oui ! La transformation arrive après le chargement suivant la méthodologie ELT (Extract > Load > Transform) et contrairement à l'ETL.
Dans cet article, je vais t'expliquer comment nous utilisons Apache Airflow et Python pour extraire et charger dans notre entrepôt les features de Mapillary. Dans un article à venir, tu pourras voir comment nous transformons cette donnée brute en une information utile à la direction des routes grâce à DBT.
Ces deux articles te rappelleront peut-être celui de Florian sur ce même sujet. Le script qu'il propose s'appuie sur les tuiles vectorielles. Notre approche quant à elle utilise les API. Deux départements limitrophes, une rivalité, et donc 2 façons de voir le monde ; le Gard ne pouvant pas faire comme l'Hérault ( Florian).
Florian).  ,
,  ,
,  , c'est parti !
, c'est parti !
Ah non ! J'ai failli oublier. Si je tiens la plume AZERTY aujourd'hui, je me dois de remercier Leo Pironti pour son travail sur le sujet. En effet, c'est Leo qui a rédigé la majeure partie du code que je m'apprête à te décrire. Ce travail, il l'a fait dans le cadre de son stage de première année de BTS SIO à la CCI du Gard. Je remercie également Romain Mazière pour m'avoir fait découvrir Apache Airflow. Allez, cette fois , , , c'est vraiment parti !!!
Apache Airflow#

Apache Airflow est un outil d'orchestration orienté data. Son rôle est de déclencher des traitements lorsque les conditions de lancement sont réunies. Il propose également une interface graphique de suivi d'exécution avec la possibilité, par exemple, de visualiser les logs et de relancer manuellement une tâche en échec.
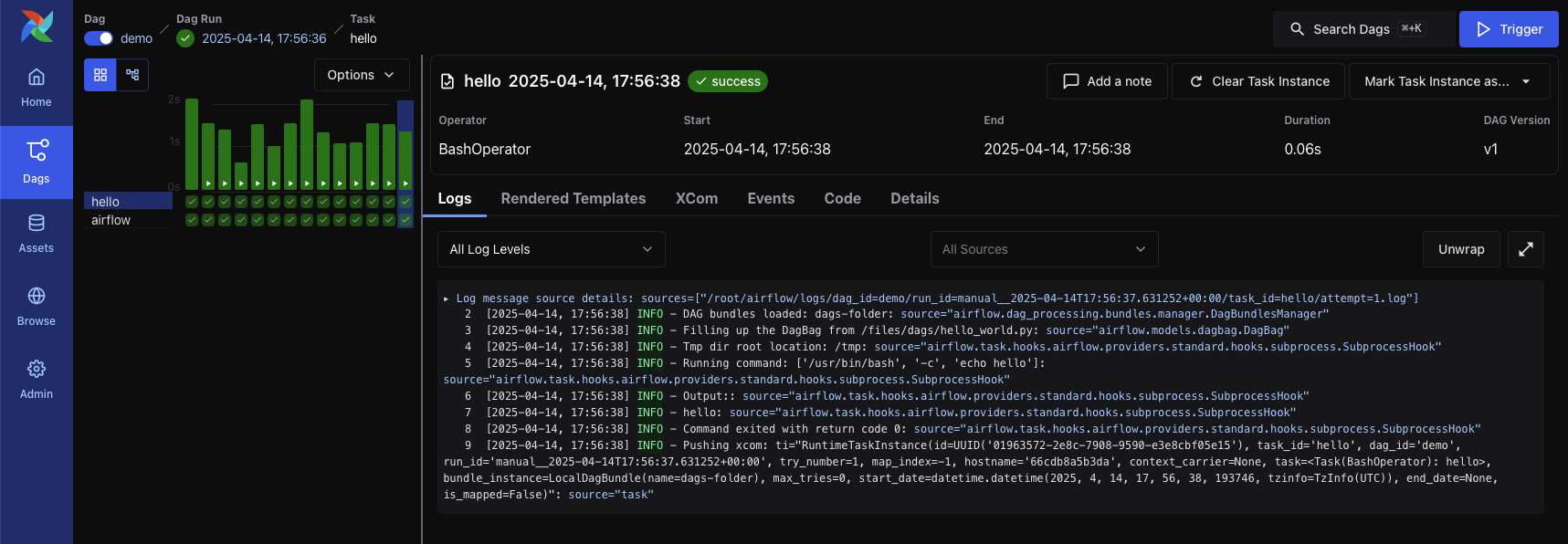
Ce n'est pas le seul outil à proposer cela, on peut par exemple citer Dagster, Prefect ou encore le français Kestra (Cocorico  !). Cependant, après étude, Apache Airflow nous a paru être la meilleure option pour répondre à nos objectifs et contraintes (voir les commentaires dans l'article de Satya pour plus de détails).
!). Cependant, après étude, Apache Airflow nous a paru être la meilleure option pour répondre à nos objectifs et contraintes (voir les commentaires dans l'article de Satya pour plus de détails).
Avant de rentrer dans le vif du sujet, voyons quelques concepts clés de l'outil.
DAG et Task#
Avec Apache Airflow, un traitement est décrit comme un graphe acyclique dirigé ; un DAG en n'english. Il s'agit d'un ensemble de tâches à exécuter, celles-ci pouvant être réalisées en séquence ou en parallèle. Un DAG a un début et une fin et il est impossible de boucler d'où le "acyclique dirigé".
Les fans de FME ou autre ETL graphique risquent d'être bousculés en découvrant que la réalisation d'un DAG se fait grâce à un script Python ; exit donc les glisser-déplacer dans une IHM, Apache Airflow adopte l'approche "as code". Ici, nous utilisons majoritairement Visual Studio Code pour construire nos DAGs mais d'autres options sont possibles.
Si elle peut faire peur, cette approche présente plusieurs avantages. Elle facilite le travail collaboratif et permet le versionning via des outils tels que Git. D'ailleurs, l'approche "as code" est plébiscitée dans d'autres domaines que celui de la data avec par exemple Terraform pour la gestion des infrastructures.
Apache Airflow propose deux syntaxes pour décrire les tâches. La première s'appuie sur des Operators c'est-à-dire des classes Python qu'il suffit d'instancier. Il en existe de nombreux parmi lesquels le BashOperator pour lancer une commande bash ou l'EmailOperator pour, tu l'as deviné, envoyer un e-mail.
Désormais, la syntaxe TaskFlow est privilégiée. Avec elle, une tâche est décrite à l'aide d'une simple fonction Python précédée du décorateur @task. Cette méthode est plus lisible car plus "pythonique".
Plusieurs options sont également disponibles pour créer un DAG mais avec TaskFlow le principe est identique ; un DAG est une fonction Python décorée d'un @dag.
À noter qu'il est possible de mixer, au sein d'un même DAG, les deux syntaxes.
Ci-dessous, un exemple de DAG pour récupérer chaque heure la hauteur d'eau du Gardon à Anduze grâce à l'API Hydrométrie de Hubeau.
import requests
from airflow.decorators import dag, task
from datetime import datetime
@dag(dag_id = "un_exemple_de_dag",
start_date = datetime(2025, 1, 1),
schedule_interval = "@hourly",
tags = ["extract", "load", "hourly"],
catchup = False)
def mon_dag():
@task(task_id = "appel_api_hubeau")
def ma_premiere_tache():
response = requests.get(
"https://hubeau.eaufrance.fr/api/v2/hydrometrie/observations_tr?code_entite=V714401001&size=1&grandeur_hydro=H"
)
response.raise_for_status()
return response.json()
@task(task_id = "isolation_hauteur_eau")
def ma_seconde_tache(response):
hauteur = response.get("data")[0].get("resultat_obs")
print("Hauteur d'eau :", hauteur)
ma_seconde_tache(ma_premiere_tache())
mon_dag()
Apache Airflow scrute à intervalles réguliers un répertoire dans lequel les fichiers .py des DAGs doivent être déposés. Aussi, il suffit d'enregistrer ce fichier à l'emplacement qui convient pour le voir apparaitre, après un petit délai d'interprétation, dans l'IHM d'Apache Airflow.
Apache Airflow 3.0 est sorti !
Au moment où j'écris ces lignes, la version 3.0 d'Apache Airflow vient de sortir.
Celle-ci arrive avec de nombreuses nouveautés. Il est désormais possible de spécifier plusieurs emplacements pour les fichiers .py des DAGs via les DAG bundles. Il semble même possible de demander à Apache Airflow de charger les DAGs directement depuis un repository Git.
Pour plus d'informations sur la version 3.0, tu peux consulter le blog d'Apache Airflow.
Scheduler, Executor et Workers#
Un DAG correspond donc à un ensemble de tâches à réaliser... Mais il faut bien que quelqu'un s'occupe de les exécuter ces tâches justement !
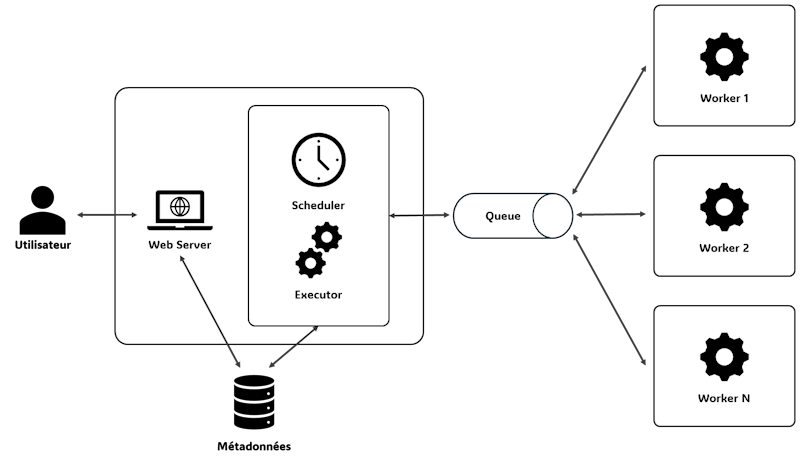
La responsabilité de l'exécution des tâches incombe à trois briques d'Apache Airflow :
- Le Scheduler : il est responsable de la planification des tâches. Il décide quand elles doivent être exécutées en fonction du calendrier de lancement et de leurs dépendances.
- L'Executor : il gère l'exécution des tâches planifiées par le Scheduler. Plusieurs natures d'Executor sont disponibles et le type à utiliser est fixé par paramétrage. Par exemple, le
CeleryExecutorest capable de distribuer l'exécution sur plusieurs serveurs. - Les Workers : ce sont les processus qui exécutent réellement les tâches. Ils reçoivent les tâches à faire du Scheduler via l'Executor.
Instances et statuts#
Un DAG et ses tâches associées décrivent les traitements à effectuer. Lorsque ceux-ci sont exécutés, on parle respectivement d'instance de DAG et d'instance de tâche.
Les instances de DAG et de tâche ont des statuts qui renseignent sur l'état de leur exécution.
Ainsi une instance de tâche passera de queued à running lorsqu'un Worker la prendra en charge. Si le traitement se termine sans erreur, l'instance prendra l'état success. Dans le cas contraire, elle sera en failed ou en up_for_retry si plusieurs tentatives ont été paramétrées.

Extraction et chargement des features#

Après cette entrée en matière sur Apache Airflow, voyons maintenant le script Python de notre DAG d'extraction et de chargement des features grâce aux API proposées par Mapillary.
Tâche 1 – création du schéma#
La première tâche de notre DAG consiste en la création du schéma d'accueil dans l'entrepôt PostgreSQL.
create_schema_task = postgresql_tasks.create_schema(taradata_storage, target_schema)
Alors oui, on ne voit pas de décorateur @task ici. C'est simplement parce que nous nous sommes créés une boîte à outils de tâches et que, la création d'un schéma étant quelque chose de courant dans nos DAGs, nous y avons intégré cette opération.
Regardons donc le code de cette fonction.
@task(task_id = "créer_schéma")
def create_schema(pg_storage: BasePostgreSQLDataStorage, schema: str):
"""
Tâche de création d'un schéma dans une base de données PostgreSQL.
pg_storage : La base de données PostgreSQL.
schema : Le nom du schéma à créer.
"""
_execute_sql_statement(pg_storage, f"create schema if not exists {schema}")
Tâche 2 – création de la table de chargement des données#
Avec cette seconde tâche, nous créons la table d'accueil des données que nous nous apprêtons à extraire.
create_table_task = postgresql_tasks.execute_sql_statement.override(task_id = "créer_table_temporaire")(
taradata_storage,
"""
drop table if exists tmp_features;
create table tmp_features(
geom geometry(polygon, 4326) primary key,
id_tache integer not null,
informations jsonb
);
""",
search_path = f"{target_schema},public"
)
Toujours pas de décorateur en vue, tout comme pour la création du schéma, le code de cette tâche est disponible dans notre boîte à outils.
Si tu es attentif, tu auras probablement remarqué que nous utilisons le type jsonb. Mais pourquoi diable faire cela ?!? La raison est simple, et nous l'avons dit plus haut, c'est parce que nous travaillons suivant un modèle ELT.
En effet, les API de Mapillary retournent les résultats au format JSON. C'est ce résultat que nous allons stocker directement dans l'entrepôt. Après tout, n'en déplaise à MongoDB, PostgreSQL se débrouille très bien avec le JSON comme nous l'explique cet autre article de Thomas.
La transformation de ces données JSON en quelque chose d'exploitable, avec QGIS par exemple, ne sera réalisée que par la suite avec DBT. Ce sera l'objet du prochain article.
Avant de poursuivre, nous devons chaîner les tâches. En effet, il ne faut pas essayer de créer la table avant d'avoir terminé la création du schéma. Ceci est fait grâce à l'opérateur >>.
Tâche 3 – calcul de l’emprise d’extraction et répartition du travail#
Bien, passons aux choses sérieuses !
L'API de Mapillary permet de récupérer les features présentes dans une bbox passée en paramètre d'appel. Cependant, la documentation précise que ce sont au maximum 2000 features qui seront renvoyées sans possibilité d'itérer sur les résultats suivants ; l'API n'étant pas paginée.
Impossible donc d'appeler l'API en y passant le rectangle englobant du Gard. Il faut travailler avec une maille plus fine.
Comme seuls les éléments à proximité du réseau routier départemental nous intéressent, nous allons calculer une grille sur l'emprise du référentiel routier et ne conserver que les cellules à proximité immédiate d'un tronçon.
Ceci est fait grâce aux 2 CTE suivantes.
with emprise as (
select ST_Collect(geom) as geom
from troncons_wgs84
),
cellules as (
select sg.geom
from emprise e
cross join ST_SquareGrid(0.01, e.geom) sg
where exists (
select *
from troncons_wgs84 t
where ST_DWithin(sg.geom, t.geom, 0.0001)
)
),
À noter que l'API attend des coordonnées en WGS84 pour la bbox, les distances sont donc exprimées en degrés. La valeur 0.01 correspond à des cellules d'environ 800 mètres * 1100 mêtres. Parmi elles, seules celles à moins de 0.0001 d'un tronçon (environ 10 mètres) sont conservées grâce à l'appel à ST_DWithin. Tout ceci est approximatif et comme Loïc nous l'a démontré dans sa série d'articles, en SIG il faut être tolérant.
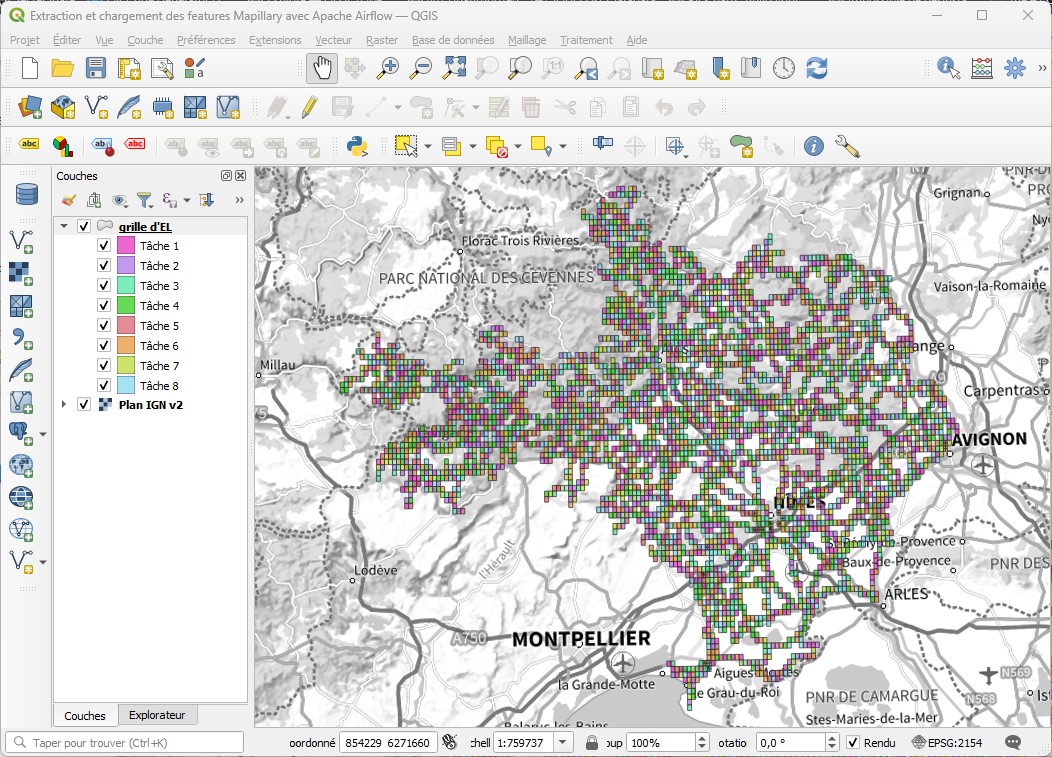
Au regard du réseau géré par le département du Gard, ce sont ici plus de 4000 cellules qui sont retournées.
Nous aurions tout à fait pu créer 4000 tâches d'extraction des features, une par cellule, mais il s'avère que cette approche n'est pas optimale... Revenons un peu sur le fonctionnement d'Apache Airflow pour comprendre.
Le Scheduler détermine les tâches à exécuter et charge l'Executor de transmettre le travail à faire aux Workers. Or, d'une part le nombre de Workers est limité. Par exemple, sur notre infra nous en avons configurés 3, chacun pouvant exécuter 4 tâches soit un total de 12 tâches en parallèle au maximum. D'autre part, le mécanisme d'attribution des tâches aux Workers prend un peu de temps. Sur des traitements massifs comme celui-ci, il est donc plus optimal de lancer moins de tâches, mais de faire faire à chacune plus de choses.
L'idée est donc de répartir ces 4000 cellules à N tâches. Ainsi, pour une valeur de N à 8, chaque tâche aura à traiter 500 cellules. Le revers de la médaille est que plus la tâche doit faire de choses, plus il y aura de choses à refaire en cas d'échec et de réexécution. Nous verrons plus bas comment nous avons géré cette contrainte.
Ci-dessous, la CTE de répartition des cellules à N tâches.
repartition_aleatoire as (
select geom, ntile(%(nb_taches)s) over(order by random()) as id_tache
from cellules
)
Ne reste plus qu'à insérer cette répartition aléatoire dans notre table de chargement, ce qui donne la requête globale suivante.
with emprise as (
select ST_Collect(geom) as geom
from troncons_wgs84
),
cellules as (
select sg.geom
from emprise e
cross join ST_SquareGrid(0.01, e.geom) sg
where exists (
select *
from troncons_wgs84 t
where ST_DWithin(sg.geom, t.geom, 0.0001)
)
),
repartition_aleatoire as (
select geom, ntile(%(nb_taches)s) over(order by random()) as id_tache
from cellules
)
insert into tmp_features (geom, id_tache)
select geom, id_tache
from repartition_aleatoire;
Nous pouvons alors afficher le résultat de cette répartition dans QGIS. De l'art cartographique !
Tâche 4 – extraction et chargement des features#
Entête et pseudo-code#
Tout est prêt pour extraire et charger les données. Histoire de ne pas rentrer directement dans le dur, analysons d'abord l'entête et le pseudo-code de la tâche.
@task(task_id = "extraire_charger_features", retries = 3)
def extract_load_features(extract_load_task_id: int):
"""
Tâche d'extraction et de chargement des "features" présentes sur l'emprise de cellules.
extract_load_task_id : Le numéro de tâche d'extraction et de chargement.
"""
# récupération de la liste des cellules à extraire/charger
# tant qu'il y a des cellules à extraire/charger
# pour chaque cellule :
# appel de l'API
# si le résultat contient moins de 2000 éléments (limite de l'API)
# alors, chargement du résultat dans la base de données
# division des cellules qui n'ont pas pu être extraites/chargées
# récupération de la nouvelle liste des cellules à extraire/charger
Cette fois, le décorateur @task est bien visible. Le paramètre task_id, déjà aperçu plus haut, permet d'identifier la tâche. Le retries quant à lui, indique à Apache Airflow de retenter l'exécution en cas d'échec. Il est également possible de définir le délai minimal entre deux tentatives via le paramètre retry_delay. En son absence, c'est la valeur par défaut qui s'applique soit 300 secondes.
La première étape consiste à récupérer la liste des cellules à extraire et charger. Ceci est fait en tenant compte du paramètre extract_load_task_id pour ne lister que les cellules attribuées à la tâche courante.
Ensuite, pour chacune des cellules, nous appelons l'API d'extraction des features.
Bien que nous ayons calculé une grille assez fine, il arrive que, sur certaines zones urbaines, 2000 éléments soient retournés. Ceci indique que la limite d'appel est atteinte ; le résultat est alors ignoré.
Si en revanche le nombre de features retournées est en dessous du seuil, alors le JSON retourné est sauvegardé en base de données.
En sortie de boucle pour chaque, les cellules qui n'ont pas de JSON associé sont celles pour lesquelles le seuil des 2000 éléments a été atteint. Celles-ci sont alors divisées en plus petites cellules de sorte à diminuer la taille de la bbox d'appel afin de passer en dessous du seuil.
De nouvelles cellules sont donc potentiellement créées à la sortie de la boucle pour chaque. Pour cette raison, la boucle pour chaque est incluse dans une autre boucle tant qu'il y a. Cette dernière récupère à chaque itération la liste des cellules à extraire et charger. Grâce à cela, la tâche ne sera terminée que lorsque les features de toutes les cellules auront été extraites.
Récupération de la liste des cellules à traiter#
Cette étape consiste simplement à exécuter la requête suivante.
select
geom,
ST_XMin(geom) as x_min,
ST_YMin(geom) as y_min,
ST_XMax(geom) as x_max,
ST_YMax(geom) as y_max
from tmp_features
where id_tache = %(id_tache)s
and informations is null
Le premier critère de la clause where permet de limiter la recherche à la tâche courante.
Le second filtre exclut les cellules pour lesquelles les features ont déjà été extraites. Ce critère intervient dans deux cas :
- D'une part, comme vu dans le pseudo-code, plusieurs itérations peuvent être nécessaires lorsque 2000 éléments sont retournés pour certaines cellules. Dans ce cas, seules les nouvelles cellules issues de la division seront retournées pour l'itération suivante.
- D'autre part, si une erreur devait survenir, par exemple en cas d'indisponibilité du réseau au moment de l'appel à l'API, ce filtre permet de ne pas avoir à retraiter la totalité des cellules lors des
retries. En effet, il serait dommage de refaire tous les appels si 90% de l'emprise a pu être traitée avant l'apparition de l'erreur.
Extraction des données#
Sur chaque cellule, l'extraction se fait via un appel HTTP à l'API en passant en paramètre les bornes de la bbox.
Nous avons encapsulé cet appel dans la fonction ci-dessous.
def call_map_features_api(cell: dict):
"""
Appel à l'API d'extraction des "features" au format JSON pour une cellule donnée.
cell : La cellule pour laquelle les "features" doivent être extraites.
"""
url = (
"https://graph.mapillary.com/map_features"
f"?access_token={mapillary_conn.password}"
"&fields=id,aligned_direction,first_seen_at,last_seen_at,object_value,object_type,geometry"
f"&bbox={cell['x_min']},{cell['y_min']},{cell['x_max']},{cell['y_max']}"
)
return http_helper.get_json(url, verify = False)
L'appel à http_helper.get_json fait référence à une fonction présente dans notre boîte à outils. Celle-ci s'appuie sur la bibliothèque Python requests.
Par ailleurs, Apache Airflow propose la gestion de connexions ce qui permet de ne pas avoir à faire apparaitre les secrets (utilisateur, mot de passe, token, ...) dans le code source. Ici, la variable mapillary_conn est globale au DAG et a été initialisée grâce à la méthode get_connection_from_secrets. Elle contient dans son champ password le token qui nous permet d'interroger l'API de Mapillary.
Chargement des données#
Le chargement des données consiste en la mise à jour du champs ìnformations (type jsonb) de la table de chargement pour la géometrie correspondante.
update tmp_features
set informations = %(informations)s
where ST_Equals(geom, (%(geom)s)::geometry);
Division des cellules non traitées#
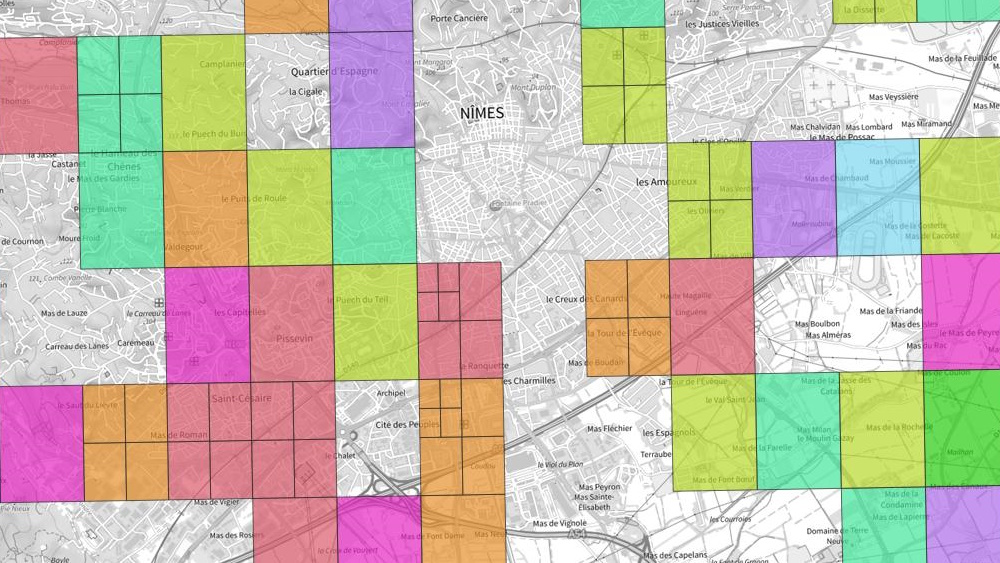
Les cellules pour lesquelles 2000 features ont été retournées sont supprimées et remplacées par 4 cellules plus petites.
La suppression et l'ajout sont réalisés en un seul ordre SQL grâce au mot-clé returning qui permet de récupérer tout ou partie des champs des lignes modifiées.
with cellules_a_diviser as (
delete
from tmp_features
where id_tache = %(id_tache)s
and informations is null
returning geom
)
insert into tmp_features (geom, id_tache)
select sg.geom, %(id_tache)s
from cellules_a_diviser cad
inner join ST_SquareGrid((ST_XMax(cad.geom)::numeric - ST_XMin(cad.geom)::numeric) / 2, cad.geom) sg
on ST_Intersects(sg.geom, cad.geom) and not ST_Touches(sg.geom, cad.geom)
Nous pouvons voir dans l'image ci-dessous que certaines cellules doivent être découpées une à deux fois pour permettre l'extraction de l'ensemble des features de l'emprise.
Invocation multiple de la tâche#
La tâche 4 est construite de sorte à traiter une sous-partie des quelques 4000 cellules pour lesquelles il faut extraire et charger les features.
Il faut donc invoquer autant de fois que souhaité la tâche pour chacune des sous-parties. Pour cela, nous mettons ces invocations dans une liste Python.
extract_load_features_tasks = []
for extract_load_task_id in range(1, extract_load_tasks_count + 1):
extract_load_features_tasks.append(extract_load_features.override(task_id = f"extraire_charger_features_{extract_load_task_id}")(extract_load_task_id))
L'appel à override permet de redéfinir les paramètres de la tâche. Nous l'utilisons ici pour mettre un intitulé distinct à chacune.
Il est ensuite possible de chaîner chaque invocation à la tâche qui précède en passant directement la liste Python à l'opérateur >>.
Tâche 5 – écrasement de la table destination#
Après chargement, la table définitive de stockage des données est écrasée avec la table de chargement. Seul le champ informations est conservé, les autres champs n'étant utiles que pour la phase d'EL.
replace_table_task = postgresql_tasks.execute_sql_statement.override(task_id = "remplacer_table")(
taradata_storage,
"""
begin;
drop table if exists features cascade;
create table features as select informations from tmp_features;
drop table tmp_features;
commit;
""",
search_path = target_schema
)
Le passage par la table temporaire tmp_features couplé à l'utilisation de la transaction begin (...) commit nous assure la cohérence de l'entrepôt. En effet, en cas d'échec, la version antérieure des données extraites et chargées reste disponible.
Planification du DAG et représentation graphique#
L'ensemble des tâches est encapsulé dans un DAG planifié de façon mensuelle.
@dag(dag_id = "extraction_et_chargement__mensuel__mapillary_com",
start_date = datetime(1993, 1, 10),
schedule_interval = schedule.get_dag_cron(tags.extract_and_load, tags.monthly),
tags = [tags.extract_and_load, tags.monthly],
catchup = False,
doc_md = dag_doc_md)
def dag():
La représentation graphique du DAG est alors visible dans l'IHM d'Apache Airflow.
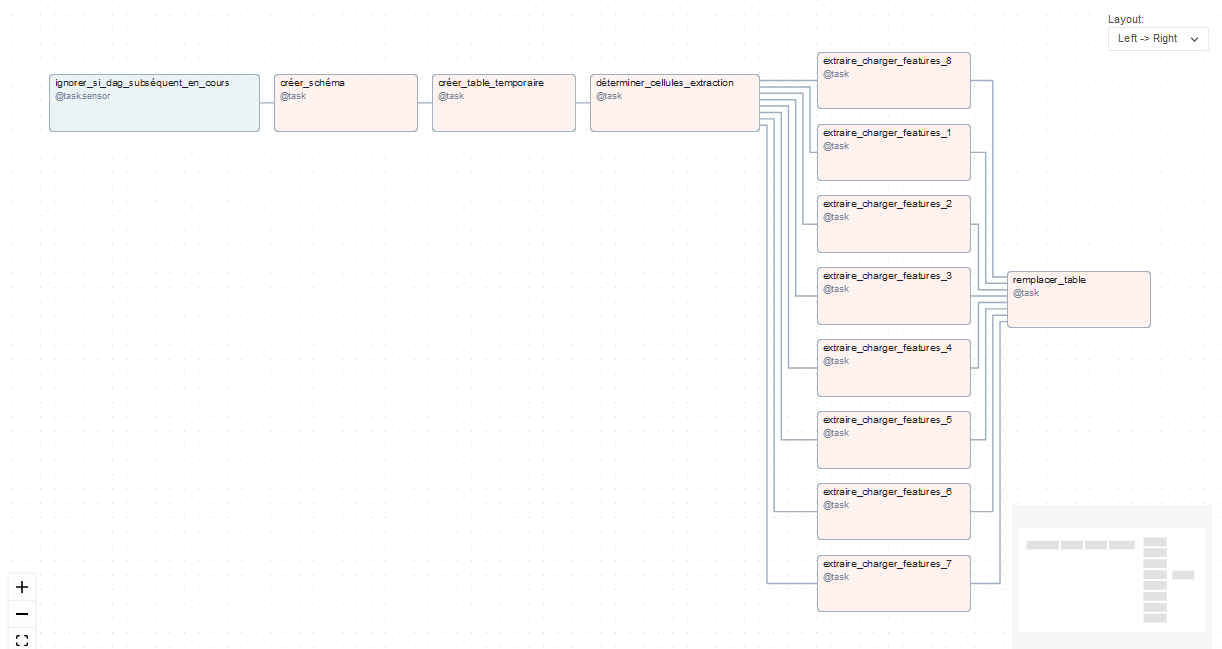
La première tâche ignorer_si_dag_subséquent_en_cours, que nous n'avons pas évoquée, permet d'ignorer le lancement du DAG si d'autres DAGs de transformation ou d'export sont en cours. L'objectif est d'assurer la cohérence des données en étant sûr que celles-ci ne soient pas écrasées au moment de leur transformation ou de leur export.
Nous pouvons voir que les 8 tâches d'extraction et de chargement ne sont pas liées entre elles. Apache Airflow aura donc la possibilité de les exécuter en parallèle.
Résultat#
La parallélisation par les workers des 8 tâches d'extraction fait que le DAG s'exécute en environ 6/7 minutes sur notre infrastructure.
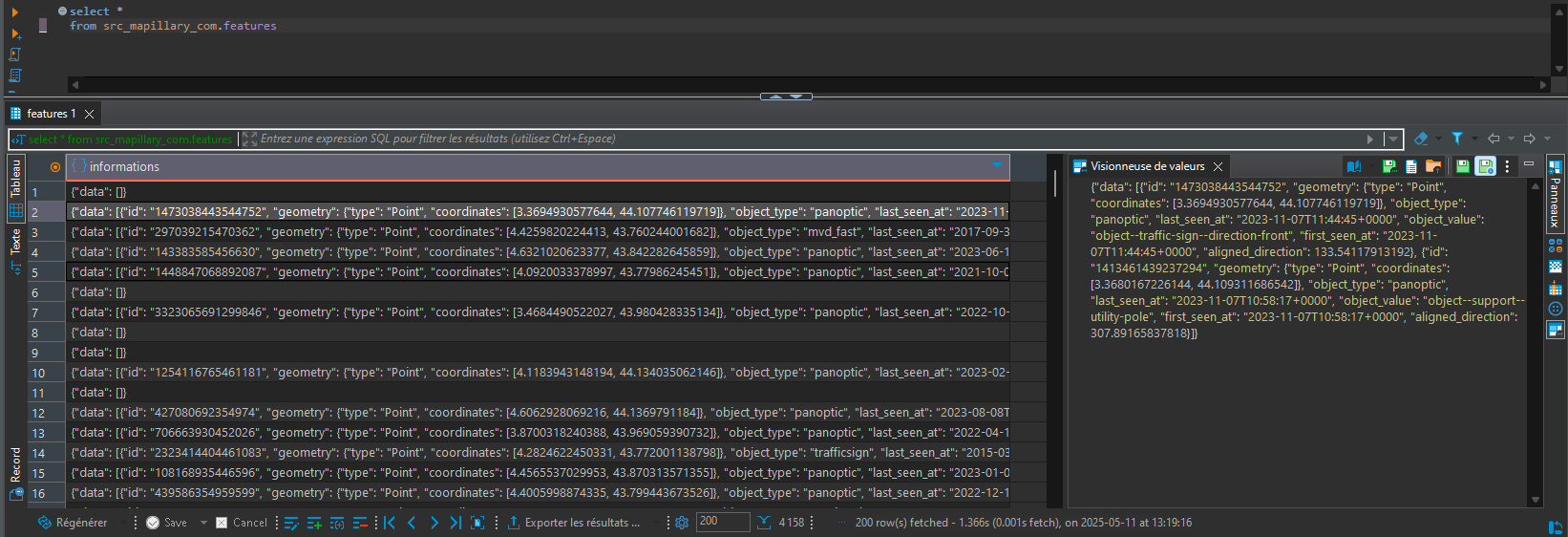
Après exécution, la table features est disponible dans le schéma src_mapillary_com de l'entrepôt.
Elle est constituée d'une unique colonne de type jsonb et contient un peu plus de 4000 lignes ; une par cellule.
Pour que tu puisses voir le DAG global, nous avons mis à ta disposition le fichier .py sur le repo Git que nous utilisons pour partager certaines ressources. C'est par ici que ça se passe.
Conclusion#
Apache Airflow est donc un outil totalement adapté à la mise en oeuvre de processus automatisés de traitement de données, que celles-ci soient géographiques ou non.
Son approche "as code" et le fait qu'il soit construit sur Python permet de profiter des nombreuses bibliothèques du langage. Par ailleurs, la syntaxe TaskFlow fait que le code à rédiger est syntaxiquement proche d'un script Python classique.
Une des forces d'Apache Airflow est qu'il est en mesure d'optimiser l'exploitation de l'infrastructure technique sous-jacente en parallélisant l’exécution des tâches indépendantes. Il est même en mesure de "scaler" les traitements sur plusieurs serveurs via par exemple le CeleryExecutor.
Il permet également le traitement de certaines erreurs par le paramétrage de plusieurs tentatives d'exécution des tâches.
Enfin, en cas d'échecs répétés, il donne la possibilité à l'utilisateur de consulter les logs d'exécution et de relancer manuellement les tâches en erreur.
Concernant le déploiement, celui-ci est facilité via les images Docker disponibles sur DockerHub.
Auteur·ice#
Michaël GALIEN#

Diplômé de Polytech'Montpellier, spécialité Informatique & Gestion, je débute ma carrière dans l'édition de logiciels. En qualité d'ingénieur-développement, je travaille sur différents projets en .NET pour le compte d'un éditeur spécialisé en Lecture et Reconnaissance Automatique de Documents (LAD/RAD).
En 2013, j'intègre le département du Gard et commence à utiliser le SIg. Je crois alors que la géomatique consiste à empiler des SHP dans ArcGIS pour faire des cartes. Et puis je découvre PostGIS, l'extension géographique de PostgreSQL avec lequel j'avais déjà travaillé dans le privé.
Après presque 10 ans au sein de la direction en charge du patrimoine routier et bâtimentaire, j'intégre en 2023 la Direction de l'Innovation et des Systèmes d'Information en tant qu'administrateur de la données. Mon rôle est d'y développer Taradata, notre stack de traitement et de valorisation du patrimoine de données départemental.
Taradata est construite suivant les principes d'une Modern Data Stack. Elle est contituée de plusieurs briques dont PostgreSQL/PostGIS, Apache Airflow, GDAL/OGR, DBT, Metabase et QGIS.
Licence #
Ce contenu est sous licence Creative Commons International 4.0 BY, avec attribution et partage dans les mêmes conditions.
Les médias d'illustration sont potentiellement soumis à d'autres conditions d'utilisation.
Réutiliser, citer l'article
Vous êtes autorisé(e) à :
- Partager : copier, distribuer et communiquer le matériel par tous moyens et sous tous formats pour toute utilisation, y compris commerciale
- Adapter : remixer, transformer et créer à partir du matériel pour toute utilisation, y compris commerciale.
L'Offrant ne peut retirer les autorisations concédées par la licence tant que vous appliquez les termes de cette licence.
Citer cet article :
"Extraction et chargement des features Mapillary avec Apache Airflow" publié par Michaël GALIEN sur Geotribu - Source : https://geotribu.fr/articles/2025/2025-05-27_taradata_extract_load_mapillary/
Commentaires
Une version minimale de la syntaxe markdown est acceptée pour la mise en forme des commentaires.
Propulsé par Isso.
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


