OSM DATA V2 : Des données à la cartographie#
 Date de publication initiale : 10 mars 2025
Date de publication initiale : 10 mars 2025
Introduction#
Dans l'article précédent, nous avons présenté les différentes possibilités d'ajout de données à OSM DATA. L'objet de cet article est d'expliciter techniquement les mécanismes mis en place pour ajouter les données.
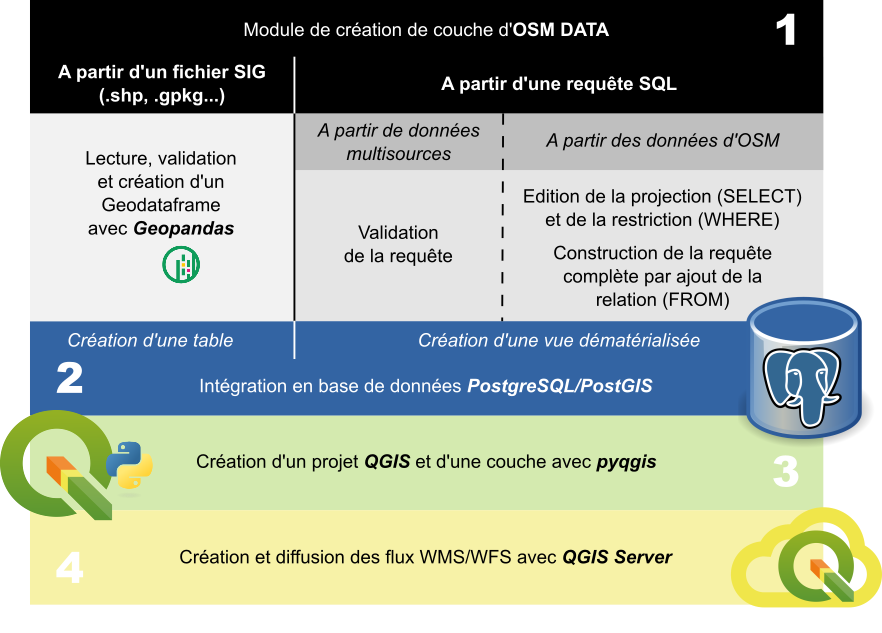
Pour rappel, quatre étapes principales permettent l'affichage des données :
- La définition puis la validation de la conformité des fichiers / requêtes SQL
- L'intégration en base de données des données sous forme de table ou de vues matérialisées
- La création d'un projet QGIS et la définition de la symbologie associée à chaque couche
- La création des flux WMS et WFS à l'aide des projets QGIS créé
Définition et validation de la conformité des fichiers / requêtes SQL#
Dans l'article précédent, le module d'ajout des données est brièvement présenté, une fonction (optionnelle) de définition du type de géométrie est aussi incluse. Pour s'assurer d'une intégration dans les meilleures conditions, un seul type de géométrie est considéré pour chaque ajout.
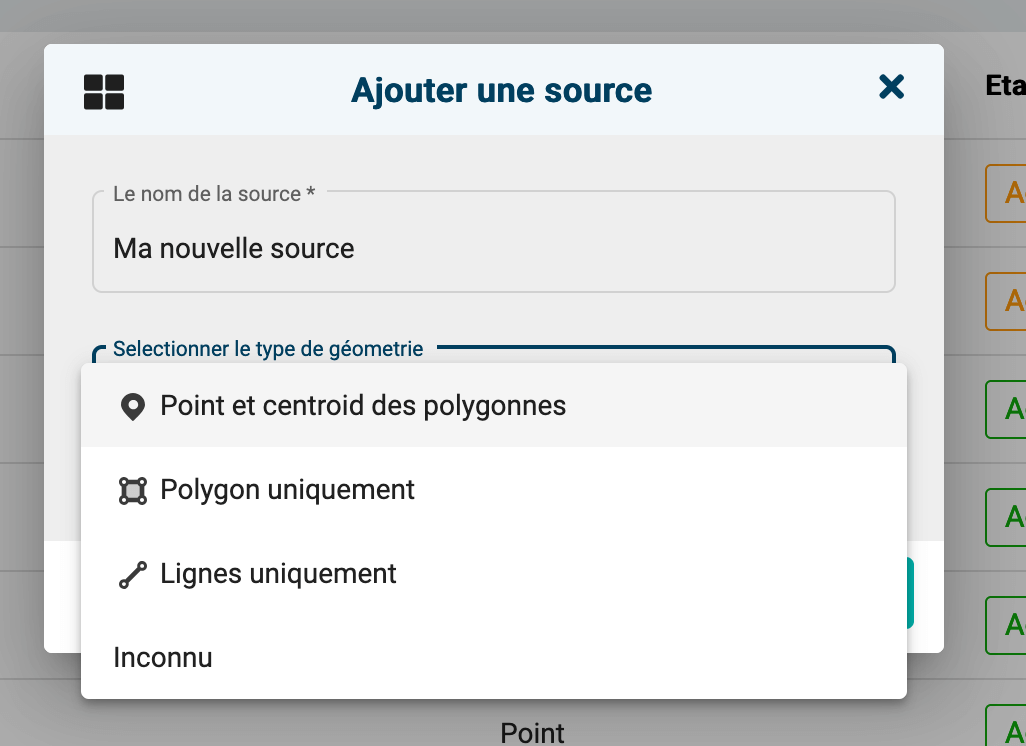
A partir d'un fichier SIG#
Pour l'ajout de fichiers SIG avec GeoPandas, la première étape est de créer un GeoDataFrame à partir des données :
# Importation du fichier SIG
import geopandas
gpdSource: geopandas.GeoDataFrame = geopandas.read_file(self.file)
Une fois le fichier interprété avec succès et le GeoDataFrame créé, deux étapes de validation sont réalisées :
-
Présence d'un seul type de géométrie :
Dans le cadre d'une mise à jour du jeu de données, on vérifie également la conformité du type de géométrie entre les données sources et les données de mise à jour. Si ce n'est pas le cas, le jeu de données de mise à jour est considéré invalide (sa définition/symbologie dans QGIS dépendant du type de géométrie du jeu de données source).
-
Présence d'entités au sein du fichier :
Une fois ces vérification effectuées, on prépare la connexion à la base de données avec SQLAlchemy :
# Connexion à la base de données
from sqlalchemy import create_engine
engine = create_engine("postgresql://{db_user}:{db_password}@{db_host}:{db_port}/{db_name}")
Enfin, l'importation en base de données est réalisé à l'aide de la commande to_postgis :
# Intégration en base de données
gpdSource.to_postgis(
name="nom_de_notre_table",
con=engine,
index=True,
index_label="id",
)
La couche est insérée en base de données ! 
À partir d'une requête SQL#
En ce qui concerne l'ajout d'un jeu de données à partir d'une requête SQL, on considère qu'une base de données est fournie avec des données d'OpenStreetMap par le biais d'osm2pgsql, un article détaille la procédure ici.
On possède donc les trois principales tables de données d'OpenStreetMap à savoir planet_osm_point, planet_osm_line et planet_osm_polygon.
La définition d'une requête SQL sur les données OpenStreetMap est simplifiée : seule la clause de restriction (WHERE) de la requête peut être définie. Ainsi, un utilisateur qui ne maitrise pas le SQL ou le schéma de la base d'OSM peut définir de nouvelles couches en s'appuyant uniquement sur le Wiki d'OpenStreetMap (exemple des stations de métro). La majorité des 350 couches présentes aujourd'hui a été créée à l'aide de cette fonctionnalité.
L'utilisateur peut aussi éditer la clause de projection (SELECT), ci-dessous un exemple de sélection des métros dans la base de données OSM. Pour cette clause, en plus de ce que l'utilisateur a défini, d'autres champs sont automatiquement ajoutés : geom, osm_id, name et tags; Le dernier champ tags regroupent les autres attributs d'OpenStreetMap disponibles sous forme de hstore.
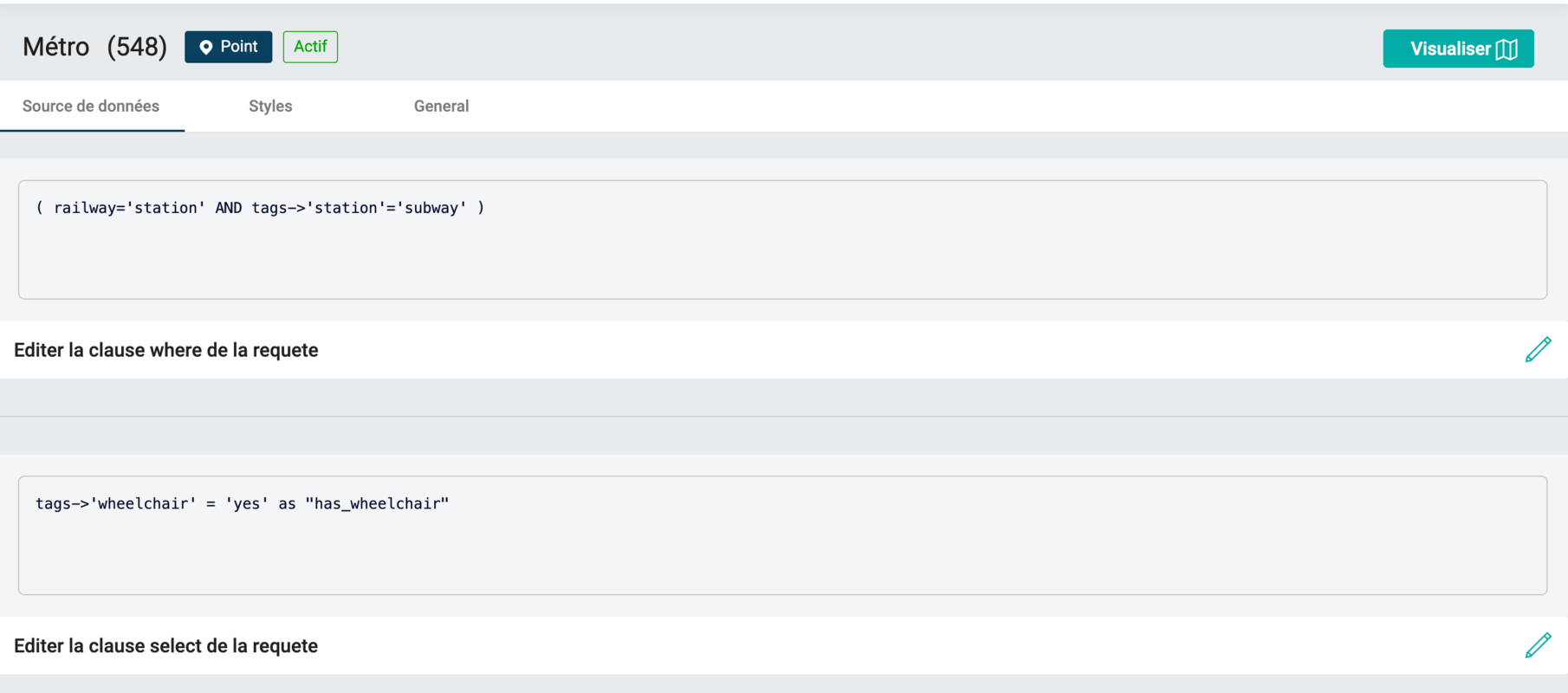
La clause source (FROM) dépend elle du type de géométrie défini lors de la création du jeu de données :
- Pour les géométrie de type
Point, la sélection est réalisée sur l'union des tablesplanet_osm_pointet les centroïdes issus de la tableplanet_osm_polygon. - Pour les géométrie de type
Polyline, seule la tableplanet_osm_lineest considérée. - Pour les géométrie de type
Polygon, seule la tableplanet_osm_polygonest considérée.
Une fois les clauses définies, un assemblage de celles-ci permet de former la requête entière. Pour l' exemple des métros :
SELECT
A.osm_id,
A.name,
hstore_to_json(A.tags),
ST_TRANSFORM(A.way,4326) as geom,
tags->'wheelchair' = 'yes' as "has_wheelchair"
FROM planet_osm_point as A
WHERE ( A.railway='station' AND A.tags->'station'='subway' )
UNION ALL
SELECT
B.osm_id,
B.name,
hstore_to_json(B.tags),
ST_TRANSFORM(st_centroid(B.way),4326) as geom,
tags->'wheelchair' = 'yes' as "has_wheelchair"
FROM planet_osm_polygon as B
WHERE ( B.railway='station' AND B.tags->'station'='subway' )
Pour valider la requête SQL, il suffit de vérifier que son exécution ne génère pas d'erreurs ! Pour rapidement connaitre la conformité de la requête, son exécution n'est pas effectuée sur toute la base de données, on limite son exécution à une seule entité par l'ajout de la contrainte LIMIT 1 en fin de script. La requête de validation est donc :
SELECT
A.osm_id,
A.name,
hstore_to_json(A.tags),
ST_TRANSFORM(A.way,4326) as geom,
tags->'wheelchair' = 'yes' as "has_wheelchair"
FROM planet_osm_point as A
WHERE ( A.railway='station' AND A.tags->'station'='subway' )
UNION ALL
SELECT
B.osm_id,
B.name,
hstore_to_json(B.tags),
ST_TRANSFORM(st_centroid(B.way),4326) as geom,
tags->'wheelchair' = 'yes' as "has_wheelchair"
FROM planet_osm_polygon as B
WHERE ( B.railway='station' AND B.tags->'station'='subway' )
LIMIT 1
En l'absence d'erreurs, une vue matérialisée est créée dans PostgreSQL. Les données d'une vue sont toujours à jour, car elles sont directement dérivées des tables sources chaque fois qu'on y accède. Les vues matérialisées offrent un mécanisme puissant pour améliorer les performances des requêtes en pré-calculant et en stockant le jeu de résultats d'une requête sous forme de table physique.
Pour OSM DATA, les requêtes peuvent faire appel à des milliers d'entités, résultant de plusieurs tables sous-jacentes, des conditions sur des champs indexés (ou non) et qui sont mises à jour une seule fois par jour. Pour toutes ces raisons, les vues matérialisées semblent être l'option la plus approriée pour notre solution.
A l'aide de la requête d'assemblage créée, la vue matérialisée est créée de la manière suivante :
Pour information, l'utilisateur PostgreSQL exécutant la requête SQL détient uniquement des droits de création de tables ou de vues dans certains schémas de la base de données afin d'éviter les mauvaises surprises.
La couche est insérée en base de données !
Création d'un projet QGIS et de la symbologie associée au jeu de données#
Création d'un projet#
La création d'un projet QGIS permet, à partir des données stockées dans la base de données PostgreSQL et de QGIS Server, de créer les flux WMS/WFS nécessaires à la visualisation des couches sur le web.
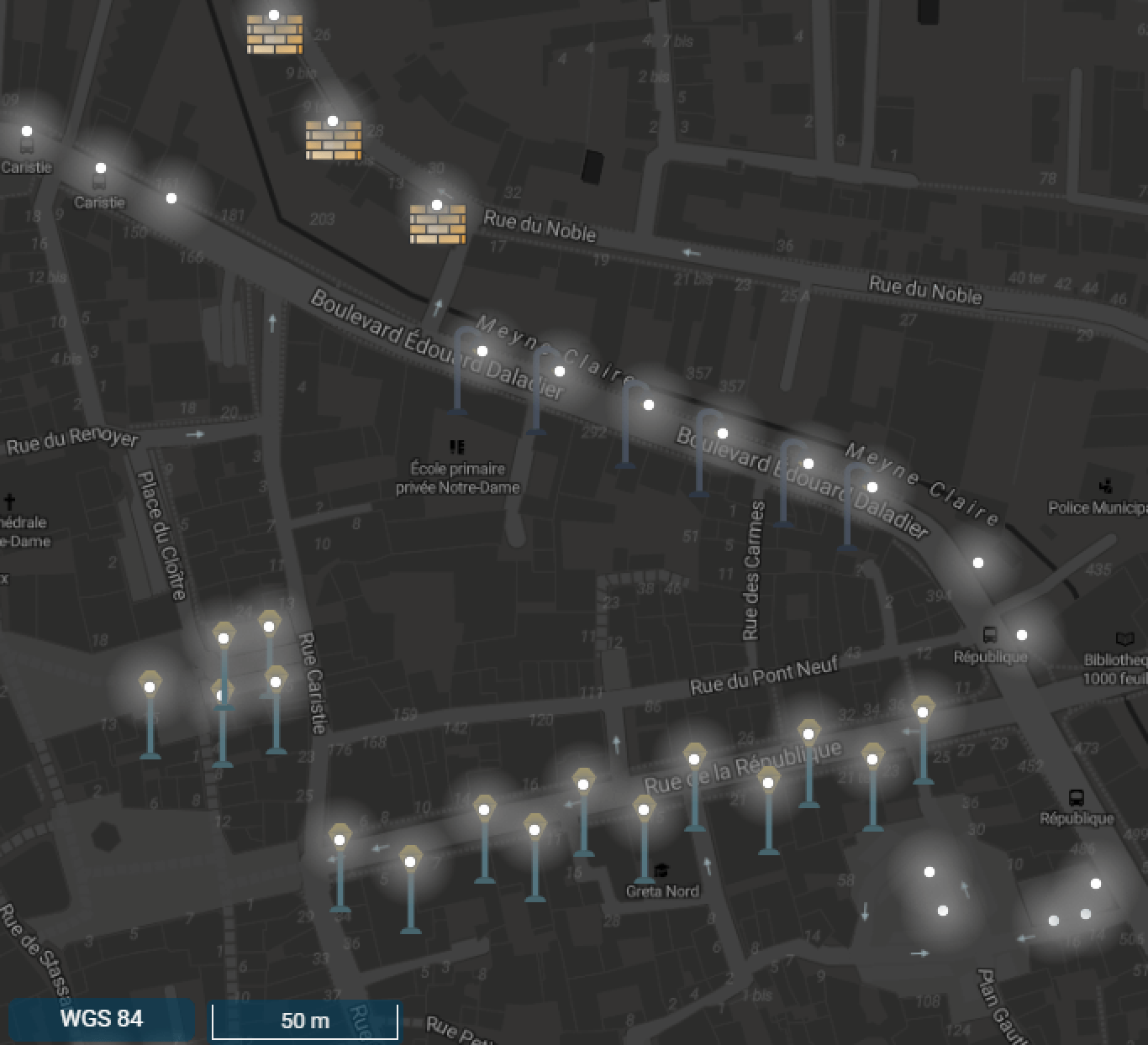
Pourquoi QGIS et QGIS Server ? Pourquoi ne pas avoir utilisé Mapserver ou Geoserver ? En deux mots : interopérabilité et efficacité. QGIS  dispose d'un moteur de style puissant et dont les capacités ne cessent de s'étoffer. Couplé à QGIS Server, la visualisation avec symbologie synchronisée desktop/web permet de créer rapidement et interactivement des symbologies, Mathieu Rajerison a par exemple mis en place différents styles :
dispose d'un moteur de style puissant et dont les capacités ne cessent de s'étoffer. Couplé à QGIS Server, la visualisation avec symbologie synchronisée desktop/web permet de créer rapidement et interactivement des symbologies, Mathieu Rajerison a par exemple mis en place différents styles :
- Les lampadaires sont discriminés en fonction de leur type de mât, du nombre de sources lumineuses, de leurs intensités...
- Les fontaines à eau sont représentées dépendammant du caractère potable ou non de l'eau
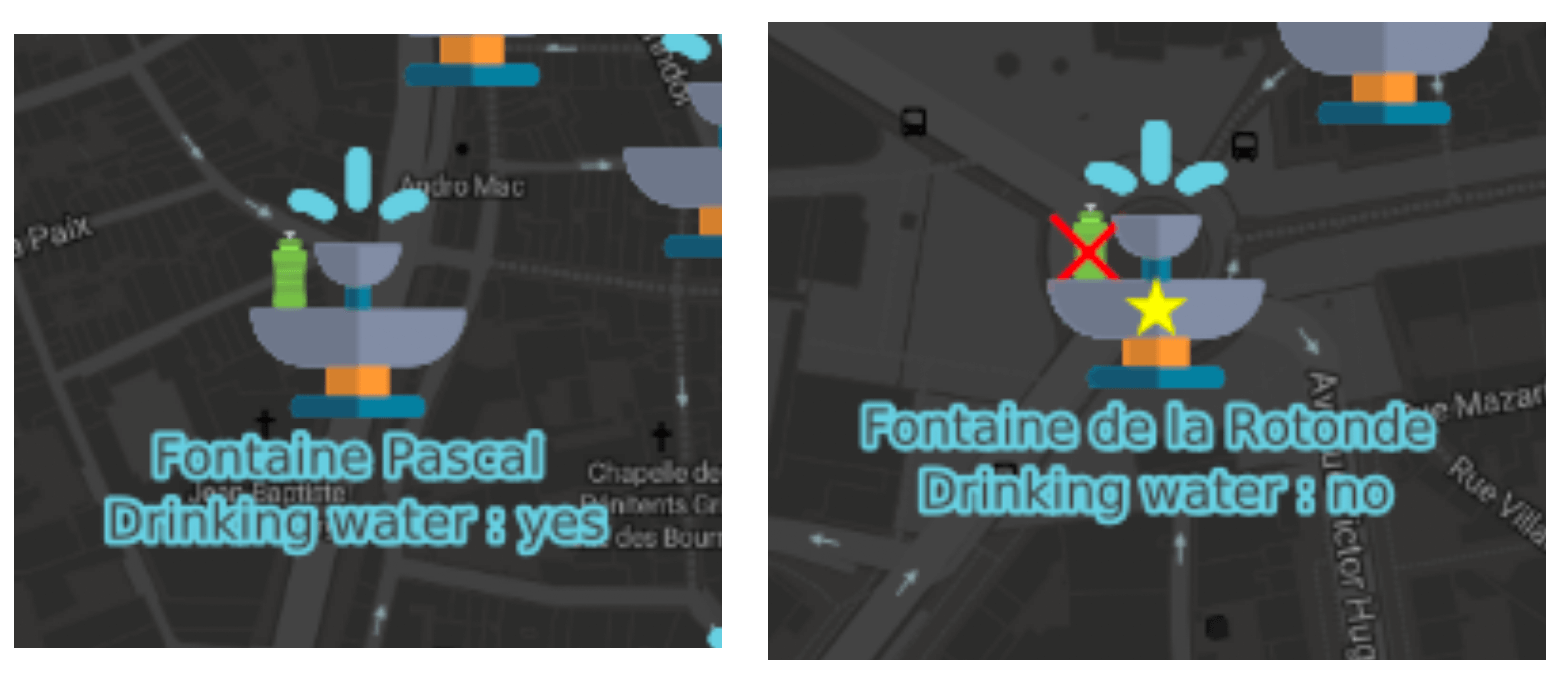
Techniquement, c'est beau, très beau, trop beau... et vous n'êtes certainement pas amoureux de Brad Pitt donc oui il y a quelques contraintes !
QGIS est avant tout un logiciel desktop donc en l'ouvrant, il initialise par défaut son environnement avec l'ensemble des dépendances qu'il juge nécessaires à une utilisation desktop. Compte tenu de notre utilisation, certaines contraintes sont soient superflues, soient limitantes en termes de performance, il est donc nécessaire de paramétrer les variables d'environnement afin de désactiver le lancement de certaines fonctionnalités (voir ci-dessous Diffusion des flux OGC WMS/WFS)).
Aussi, si on considère le lancement d'un projet ne contenant qu'une couche, l'initialisation peut être rapide, lorsque le projet dispose de 350 couches, c'est moins évident.

Pour ces raisons et sans avoir encore eu l'occasion de faire une analyse de l'outil PerfSuite, il a été décidé de répartir les couches entre plusieurs projets QGIS avec un maximum de 5 couches par projet. Sur OSM DATA, il y a actuellement 139 projets répertoriés :
# Décompte des projets QGIS d'OSM DATA
debian@osm_data:provider/qgis/project$ ls | grep '\.qgs$' | wc -l
139
# Liste des projets QGIS d'OSM DATA
debian@osm_data:provider/qgis/project$ ls | grep '\.qgs$'
projet_0.qgs
projet_1.qgs
projet_10.qgs
projet_100.qgs
...
Pour créer un projet QGIS relié à un jeu de données, il est donc nécessaire d'établir une nomenclature structurée dépendante de la contrainte de "5 jeux de données maximum par projet". Ainsi, pour lancer la création d'un projet associé à un nouveau jeu de données, voici le script utilisé :
from qgis.core import QgsProject
# Nomenclature du projet QGIS
path_to_qgis_project = "projet" + "_" + str(int({nombre_total_de_couches_existantes} / 5)) + ".qgs"
# Création du projet QGIS
project = QgsProject()
project.read(path_to_qgis_project)
project.write()
Si le projet existe déja il est utilisé, et s'il n'existe pas, le projet est créé.
Une fois le projet QGIS sélectionné/créé, on ajoute le nouveau jeu de données avec pour source la table ou la vue matérialisée précédement créée :
from qgis.core import QgsProject, QgsDataSourceUri
# Création de la connexion à la base de données
uri = QgsDataSourceUri()
uri.setConnection(host, port, database, user, password)
# Création de la source de données avec le nom de la table ou la vue, le schéma, le champ de géométrie et celui de la clé primaire
uri.setDataSource({schema_de_la_table_ou_vue}, {table_ou_la_vue}, {champ_de_geometrie}, "", {cle_primaire})
# Création d'une couche de type vecteur avec la source définie
vector_layer = QgsVectorLayer(uri.uri(False), {layer_name}, "postgres")
# Validation d'accès à la table / vue et ajout de la couche au projet
if vector_layer.isValid():
project.addMapLayer(vector_layer)
# Pour que la couche soit disponible en WFS, ajout de celle-ci dans la balise WFSLayers.
project.writeEntry("WFSLayers", "", [vector_layer.id()])
project.writeEntry("WMSAddWktGeometry", "", "true")
# Sauvegarde du projet
project.write()
Une fois le projet QGIS créé, les données peuvent déjà être diffusées sous forme de flux WMS/WFS avec QGIS Server ! Cependant, afin d'améliorer leur visualisation, le style doit être défini.
Définition et application du style par l'utilisateur#
Dans la fenêtre de définition d'une couche sur OSM DATA, un onglet Styles permet de définir une ou plusieurs symbologies pour chaque jeu de données :
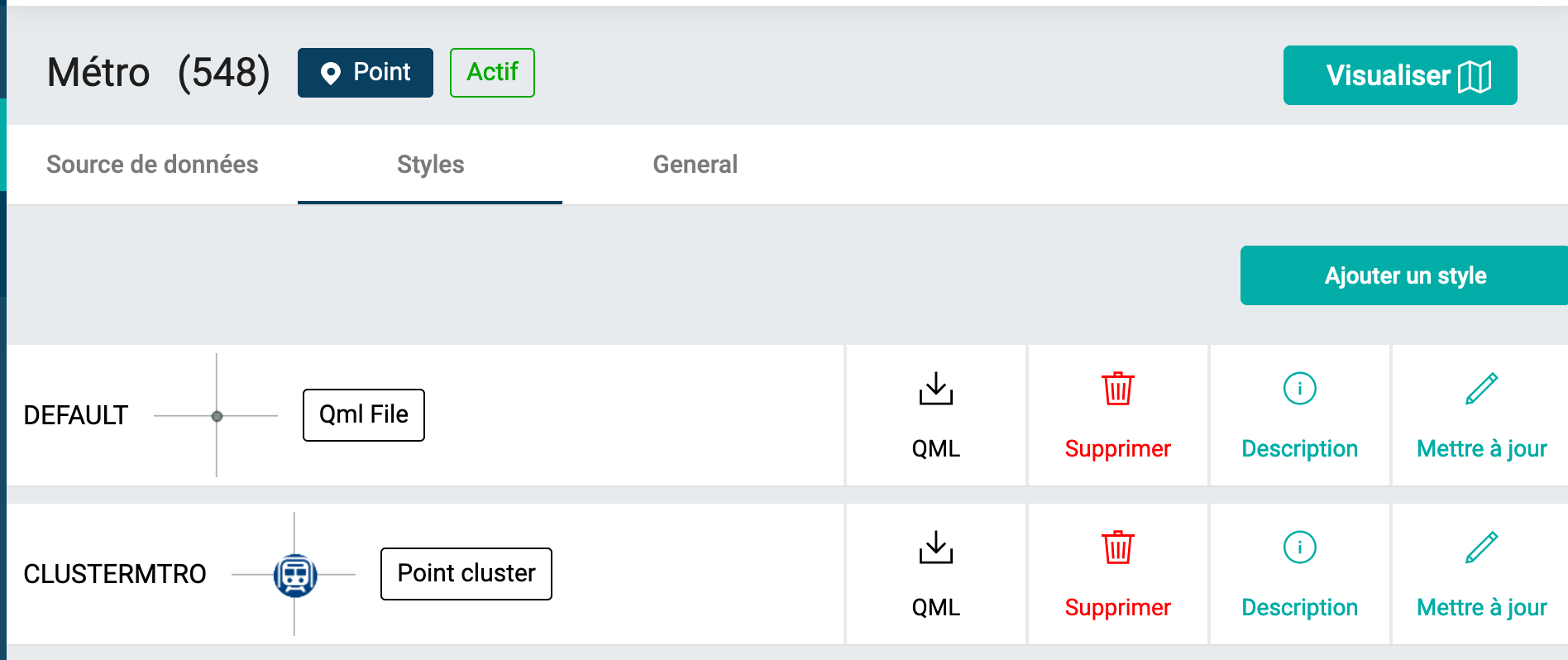
Cette caractéristique multi-styles découle de la fonctionnalité déjà présente au sein de QGIS. Les différentes manières de définir un style dans OSM DATA permettent de faciliter l'administration des jeux de données depuis l'interface, deux options sont disponibles :
- A l'aide d'un fichier QML directement préparé à partir de QGIS
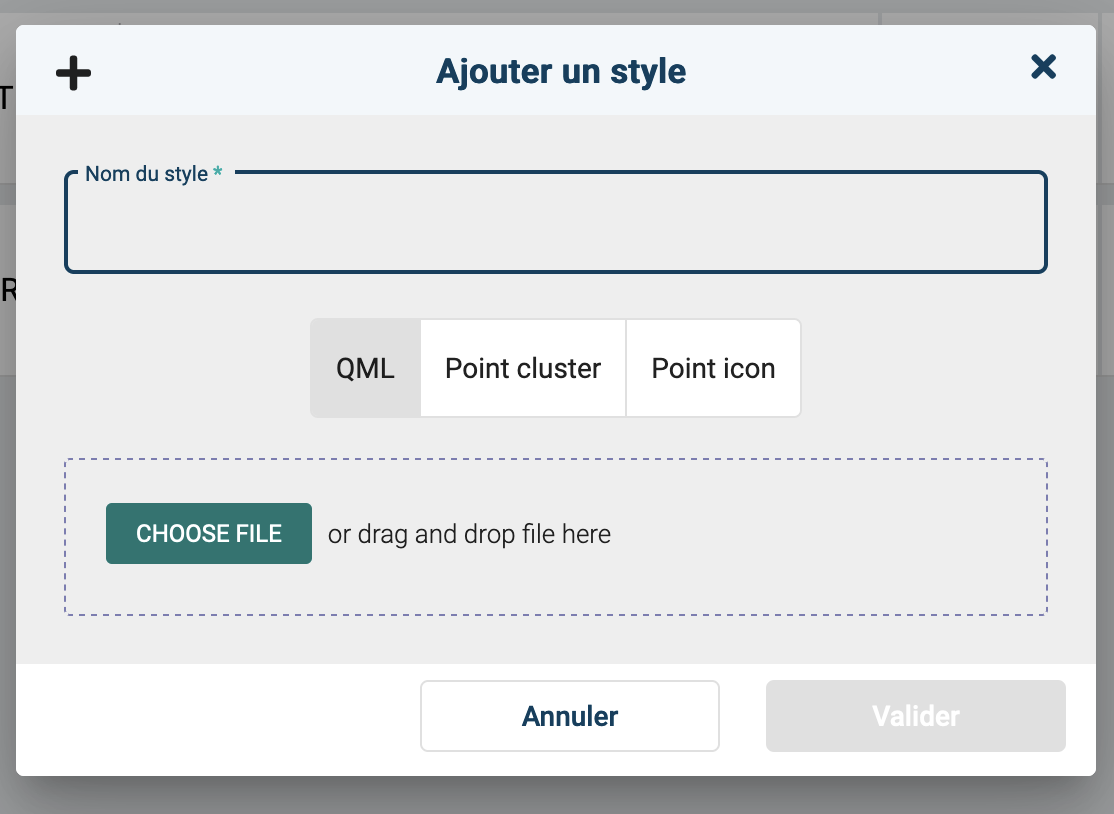
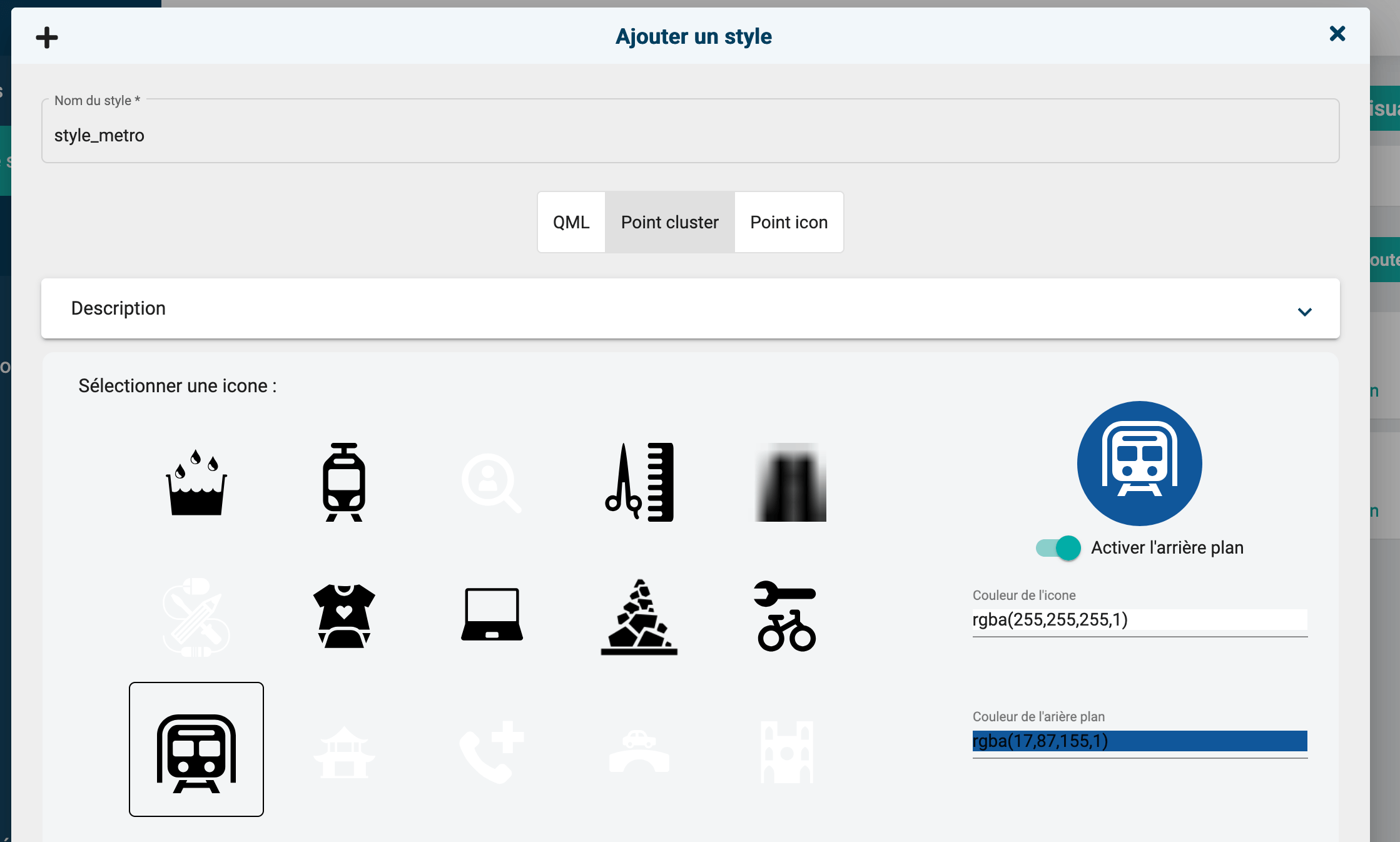
- A l'aide du moteur de style intégré d'OSM DATA :
- Sous la forme d'un icone ponctuel : L'utilisateur fournit un icône (raster ou vecteur), un style est créé avec
QgsSingleSymbolRendereret PyQGIS pour l'appliquer au jeu de données. Le détail de l'implémentation est disponible sur le GitHub du projet. - Sous la forme d'un regroupement de point (cluster) : L'utilisateur fournit un icône, un style est créé avec
QgsPointClusterRendererpour l'appliquer au jeu de données. Le détail de l'implémentation est disponible sur le GitHub du projet.
- Sous la forme d'un icone ponctuel : L'utilisateur fournit un icône (raster ou vecteur), un style est créé avec
Au besoin, un dernier article peut compléter cette série pour expliciter davantage la création de styles avec PyQGIS.
Diffusion des flux OGC WMS/WFS#
Pour utiliser QGIS Server, rien de plus simple ! Il suffit d'enregistrer le projet QGIS dans un dossier et cet article détaille les étapes d'exploitation de ce dossier pour créer les flux OGC.
Cependant, nous avons évoqué plus haut qu'à ce jour 139 projets QGIS sont présents. Une seule instance QGIS ne peut pas gérer l'ensemble de ces données de manière efficace. Pour cela, py-qgis-server est utilisé, il permet de définir plusieurs instances sur plusieurs workers, améliorant ainsi les performances. De plus certaines variables d'environnement QGIS sont directement exposées, voici celles qui sont actuellement activées sur OSM DATA lors de l'initialisation d'un projet :
- Ignorance des composeurs d'impression du projet
- Ignorance de la validité des couches
Après avoir exploré le mécanisme d’ingestion et de diffusion des données par OSM DATA, nous pouvons désormais nous intéresser à ses fonctionnalités récentes, notamment la visualisation des données en 3D. Ce sera l’objectif du prochain article.
1 : Introduction à OSM Data 3D
Auteur·ices#
Karl TAYOU#
Passionné et curieux par tout ce qui tourne au tour du SIG, 3D et OpenStreetMap.
Principal développeur de demo.openstreetmap.fr
Romain LATAPIE#
Géomètre de formation, j'ai découvert l'open-source au fil de relevés topographiques/bathymétriques et du développement d'outils géospatiaux au Québec pour Tetra Tech. Revenu en France en 2022, je me suis intéressé à la modélisation 3D et au BIM avec FUTURMAP. Je travaille désormais à Siradel, toujours avec un projet QGIS / PostGIS sous le coude !
Licence #
Ce contenu est sous licence Creative Commons International 4.0 BY-NC-SA, avec attribution et partage dans les mêmes conditions, sauf dans le cadre d'une utilisation commerciale.
Les médias d'illustration sont potentiellement soumis à d'autres conditions d'utilisation.
Réutiliser, citer l'article
Vous êtes autorisé(e) à :
- Partager : copier, distribuer et communiquer le matériel par tous moyens et sous tous formats
- Adapter : remixer, transformer et créer à partir du matériel pour toute utilisation, exceptée commerciale.
Citer cet article :
"OSM Data : des données SIG jusqu'au serveur cartographique" publié par Karl TAYOU, Romain LATAPIE sur Geotribu sous CC BY-NC-SA - Source : https://geotribu.fr/articles/2025/2025-03-10_osm-data-3D-02-donnees-diffusion/
Commentaires
Une version minimale de la syntaxe markdown est acceptée pour la mise en forme des commentaires.
Propulsé par Isso.
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


