L’enjeu de la data au département du Gard#
 Date de publication initiale : 25 février 2025
Date de publication initiale : 25 février 2025

Le département du Gard dispose de plusieurs compétences parmi lesquelles l'aide sociale et l'infrastructure routière. Il entretient et améliore un réseau de 4 600 km de routes afin de sécuriser les déplacements.
L’éducation fait également partie de ses missions, notamment à travers la gestion de 53 collèges publics. À cela s’ajoutent d’autres domaines importants comme la culture et les archives départementales.
Dans chacun de ces domaines, une grande quantité de données est produite et consommée, c'est ce patrimoine de données que le département souhaite valoriser pour notamment aider les directions et services à prendre les décisions éclairées dans l'exercice de leurs missions.
Auparavant, les analyses se faisaient plutôt dans des silos métiers mais aussi des silos techniques avec une séparation BI/SIG. Or, le croisement de données de natures et de sources diverses peut apporter de l'information.
C'est pourquoi une étude a été menée auprès de différents acteurs de l'écosystème data afin de définir une stratégie de valorisation des données. Un département c'est avant tout un territoire, cela implique que les données que nous traitons sont en grande partie géolocalisées. Notre volonté était de ne pas séparer les données classiques et les géo-données dans deux systèmes distincts, mais de les traiter et de les valoriser dans une même architecture.
L'objectif de l'étude était donc de tirer les meilleures pratiques de chacun et d'adapter la démarche à nos besoins.
Il va donc être question pour la suite, de te présenter la démarche mise en place ainsi que les outils retenus par le département du Gard pour valoriser son patrimoine de données.
Vers un nouveau modèle Data#
L'analyse s'est faite auprès d'acteurs dans le secteur public (les confrères territoriaux), le secteur privé mais aussi auprès de responsables de masters universitaires dans le domaine de la géomatique.
1. Ce que nous avons appris#
En se renseignant auprès de nos confrères du secteur public, nous nous sommes rendu compte qu'aucun modèle ne se dégageait véritablement. Et plus encore, nous avons souvent constaté une séparation entre data et SIG.
Du côté du secteur privé, nous avons retenu plusieurs choses, notamment un modèle qui semble l'emporter : La Modern Data Stack.
Pour définir une Modern Data Stack (MDS), le plus simple est de la comparer avec un modèle traditionnel (TDS).
Le modèle traditionnel est souvent construit autour d'un outil unique et propriétaire installé localement (On-Premise). À l'inverse, la Modern Data Stack est plus modulaire. Plusieurs outils y sont combinés, chacun ayant un rôle dédié de la collecte à la valorisation des données. Ceux-ci sont en général Open Source et hébergés sur le Cloud en mode SaaS.
Par ailleurs, le modèle de traitement diffère. En traditionnel, l'approche ETL (Extract Transform Load) est privilégiée c'est-à-dire que la transformation de la donnée est préalable à son intégration dans l'entrepôt. En MDS, les données sont d'abord importées avant d'être transformées ; on parle d'ELT (Extract Load Transform).
Pour résumer, ces différences peuvent être synthétisées dans le tableau suivant :
| Caractéristique | Traditional Data Stack | Modern Data Stack |
|---|---|---|
| Architecture | Monolithique / Graphique (ex. FME) | Modulaire / As Code |
| Hébergement | Logiciels On-Premise | Cloud / SaaS |
| Logiciels | Fermés, propriétaires | Plus ouverts, souvent Open Source |
| Approche de traitement | ETL (Extract, Transform, Load) | ELT (Extract, Load, Transform) |
Si tu as envie de creuser un peu, laisse-moi te recommander quelques ressources en ligne :
- Définition et avantages d'une MDS : https://datascientest.com/modern-data-stack-tout-savoir
- MDS expliquée en vidéo par Michael Kahan (la vidéo est en anglais, sous-titres disponibles) : https://www.youtube.com/watch?v=GVyuPHumef8
- ETL vs ELT (sous-titres dispo) https://www.youtube.com/watch?v=_Nk0v9qUWk4
2. Notre stratégie#
Notre objectif initial était de réunir les données classiques et géographiques au sein d'un même système, afin de tirer parti de leur complémentarité. Pour y parvenir, nous avons élaboré une stratégie consistant à construire un modèle de traitement des données inspiré des principes de la Modern Data Stack, tout en l'adaptant pour répondre aux spécificités liées à la composante géographique.
Taradata : notre Data Stack#
La stack mise en oeuvre au département porte le nom de Taradata.
Bien qu'inspirée des principes de la MDS, Taradata n'en est pas une version stricte. En effet, nos logiciels ne sont pas hébergés sur le Cloud, mais plutôt On-Premise / Docker. Cependant, nous avons conservé les éléments essentiels d'une MDS, comme la modularité et l'approche ELT.
Son utilité#
Nous devons traiter les données dites « attributaires » et « géographiques ».
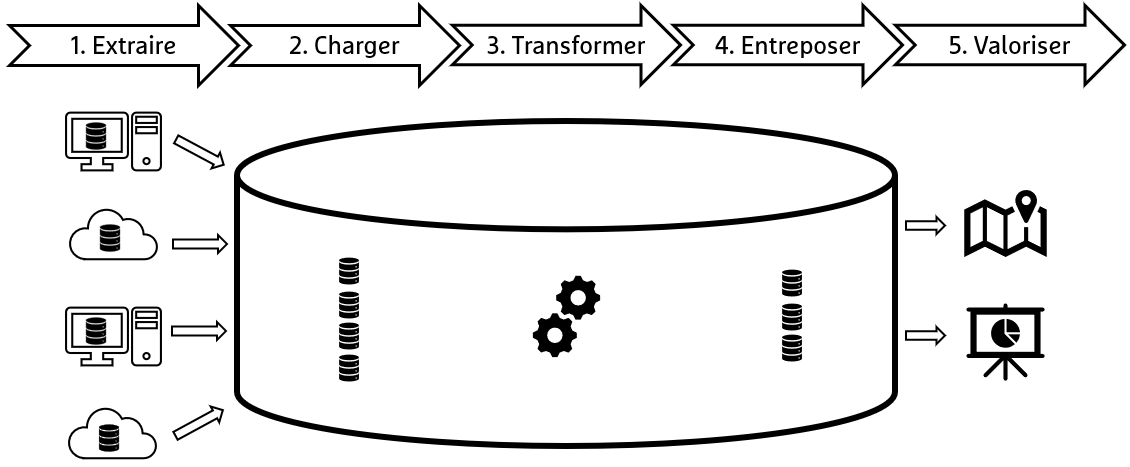
Cela implique :
- Extraire les données provenant de sources variées comme les bases de données, les API, les données issues d’IoT, etc.
- Charger ces données dans un entrepôt.
- Transformer ces données via renommages, restructurations et associations.
- Entreposer dans une base de données.
- Valoriser ces données via des tableaux de bords, cartographie, etc.
Voici le principe de la stack simplifié au travers d'un schéma :
Les outils#
Mettre en place une Modern Data Stack, c'est choisir les différentes briques qui la constituent, nous allons détailler ici les outils retenus pour Taradata.
PostgreSQL/PostGIS#

Pour l'entrepôt de données, nous avons retenu PostgreSQL/PostGIS simplement car nous n'avons pas trouvé d'équivalence en termes de traitement pour la composante géographique dans les moteurs les plus utilisés en MDS.
À titre d'exemple GoogleBigQuery et Snowflake, qui sont deux entrepôts de données Cloud, disposent, au moment où j'écris ces lignes, respectivement de 67 et 70 fonctions géographiques, alors que PostGIS en propose plus de 500.
Extraction et chargement : GDAL/OGR (ogr2ogr)#

ogr2ogr permet d'extraire et charger des données :
- de différentes natures (notamment des données géographiques),
- de différents formats (CSV, SHP, GPKG, GeoJSON...),
- de différentes sources.
Voilà à quoi pourrait ressembler une extraction de données au format GeoJSON par un appel API avec au passage une transformation du système de coordonnées.
PG:"dbname='<dbname>' host ='<host>' port='5432' user='***' password='***'"
-f PostgreSQL
GeoJSON:"https://data.sncf.com/api/explore/v2.1/catalog/datasets/liste-des-passages-a-
niveau/exports/geojson?select=id_if%2Clibelle%2Cmnemo%2Cobstacle%2Ccode_ligne%2Crg_troncon%2Cdiffr%2Cc_geo
&where=in_bbox%28c_geo%2C43.15738485671127%2C%201.839594309811448%2C%2045.36619392221315%2C%205.8304424666
54746%29"
-s_srs EPSG:4326
-t_srs EPSG:2154
-lco SCHEMA=src_data_sncf_com
-lco OVERWRITE=YES
-nln passages_a_niveau
A ce stade, les données sont chargées dans l'entrepôt mais de façon brute. Nous avons donc besoin d'un outil pour les transformer.
Transformation : Data Build Tool (DBT)#

Dans le paragraphe qui précède, nous avons vu comment OGR nous aide à charger les données. Il faut maintenant les transformer. Ça tombe bien, pour la transformation nous avons retenu DBT, un logiciel dont la version Core est Open Source sous licence Apache et utilisable en lignes de commandes. Il existe également une version Cloud.
C'est un peu un abus de langage de dire qu'il transforme les données simplement car c'est l’entrepôt, soit dans notre cas PostgreSQL/PostGIS qui s'en charge. On peut dire que DBT a pour rôle de commander les transformations.
Les transformations sont décrites en SQL/Jinja. Voici par exemple une transformation des données de la Base Adresse Nationale (BAN) lors de l'étape dite de staging :
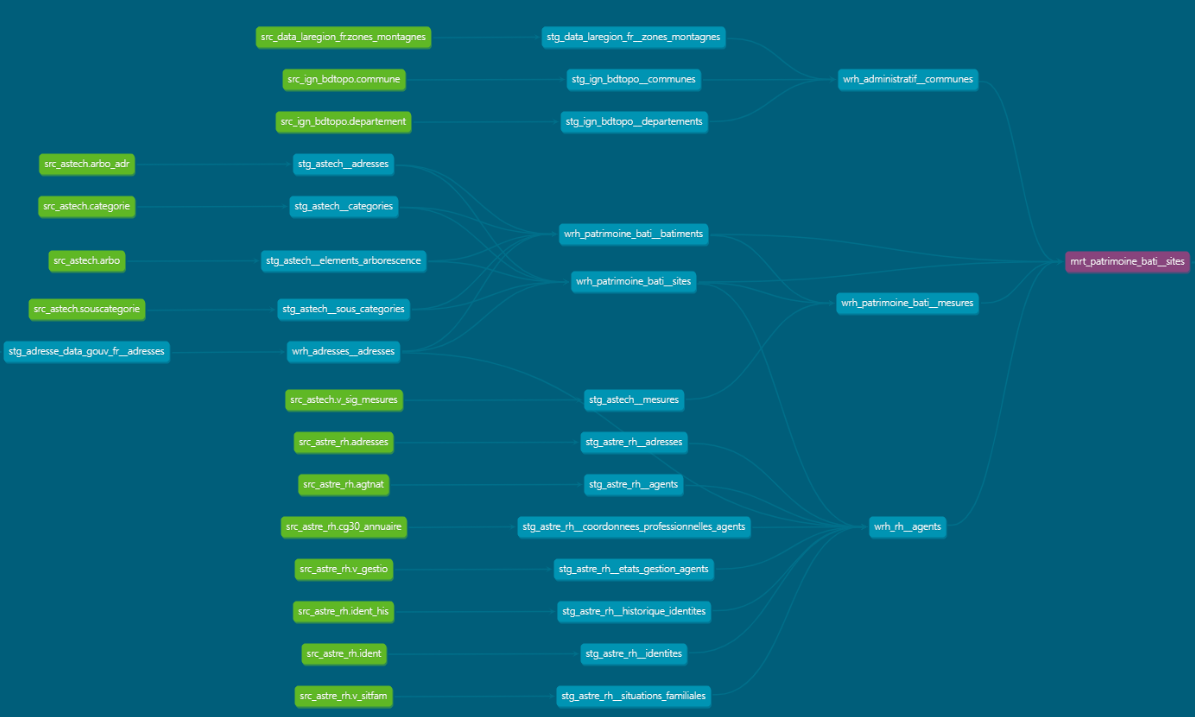
Le logiciel permet aussi de connaître le lignage de la donnée c'est-à-dire la capacité à visualiser et tracer l'origine, les transformations, et les relations entre les différentes données. Voici un extrait de lignage avec les données sources en vert, la donnée finale en violet et toutes les liaisons.
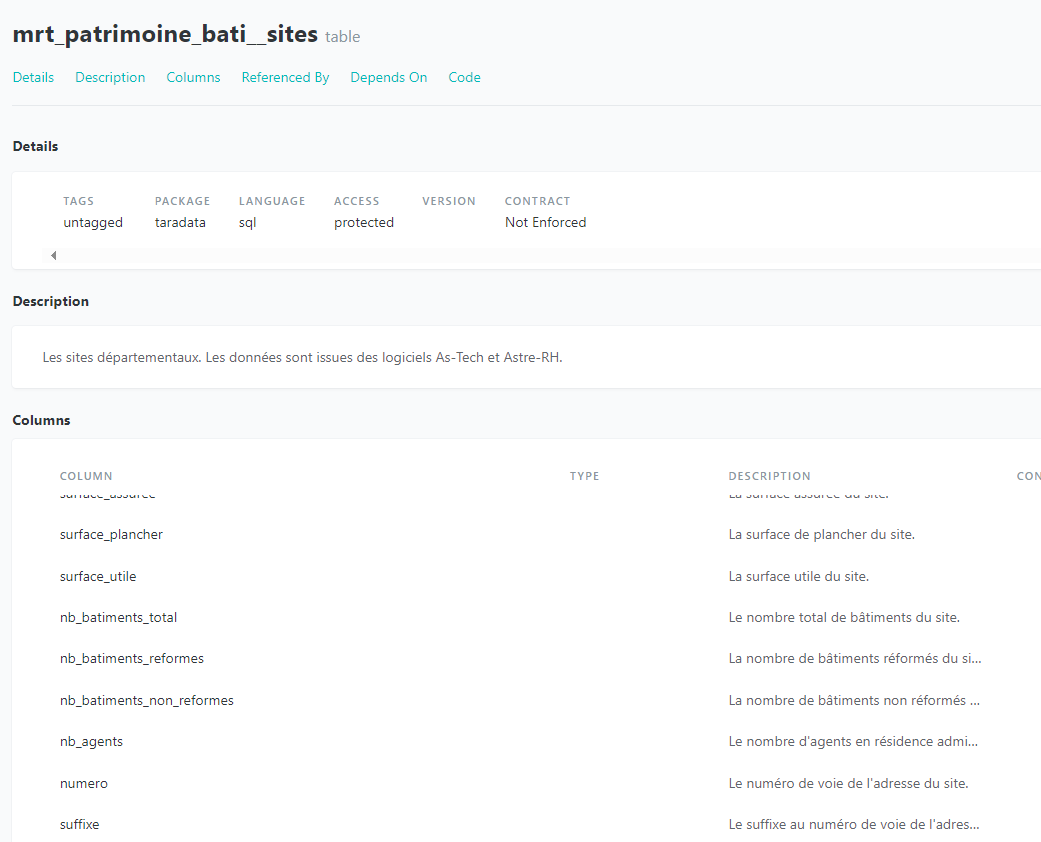
Documenter les données est aussi une possibilité que nous offre le logiciel.
Pour aller plus loin, je te conseille vivement la playlist DBT, toujours de Michael Kahan qui est une excellente source d'apprentissage et qui te détaillera bien plus les spécificités du logiciel que moi.
Orchestration : Apache Airflow#

Apache Airflow est l'orchestrateur, la clé de voûte de toute la stack. Son objectif est de décrire les tâches à réaliser et planifier leur exécution.
Dans Airflow, les tâches sont définies et organisées dans ce qu’on appelle un DAG (Directed Acyclic Graph), une structure qui permet de représenter les relations et l’ordre d’exécution des tâches. Ces tâches sont créées à l'aide de scripts Python (car Airflow est écrit en Python)
Et donc Airflow nous permet de :
- définir les tâches en Python,
- spécifier les contraintes entre les tâches,
- organiser les tâches dans un DAG,
- planifier l’exécution des DAGs et suivre leur avancement.
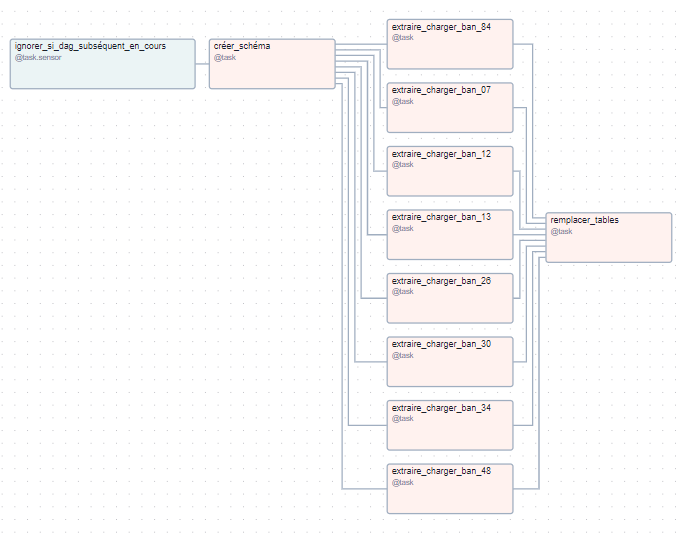
Tu peux trouver ci-dessous une représentation graphique des différentes dépendances entre les tâches d'un DAG d'extraction et chargement des données de la BAN concernant le Gard ainsi que ses départements limitrophes.
Valorisation avec Metabase et QGIS#

Après avoir fait ce cheminement, il faut bien que nos données servent à quelque chose. On a justement au travers de Metabase tout un champ de possibilités concernant la représentation de nos données transformées. C’est l’outil de Data Visualisation.
Dans l'idéal, nous aurions souhaité un outil aussi performant en dataviz qu'en représentation cartographique mais cet outil n'existe vraisemblablement pas encore, donc nous complétons ça avec QGIS. Metabase est limité en carto certes (pas de carte multi-couches, pas de gestion de la symbologie), mais il est auto hébergé et permet de produire des tableaux de bord de manière autonome.
Voyons un peu les actions qu'il permet de faire :
- Interroger l’entrepôt en mode graphique.
- Représenter les données sous différentes formes.
- Combiner plusieurs visualisations dans des tableaux de bord.
- Ajouter des filtres interactifs sur les données affichées.
Interaction avec les données#
Découvrons justement ce qu'il est possible de faire avec Metabase au travers d'un cas d'usage.
L'exemple ci-dessous, réalisé en collaboration avec la direction des bâtiments, te montre la localisation ponctuelle des différents sites présents dans le département (collèges, actions sociales, ...).
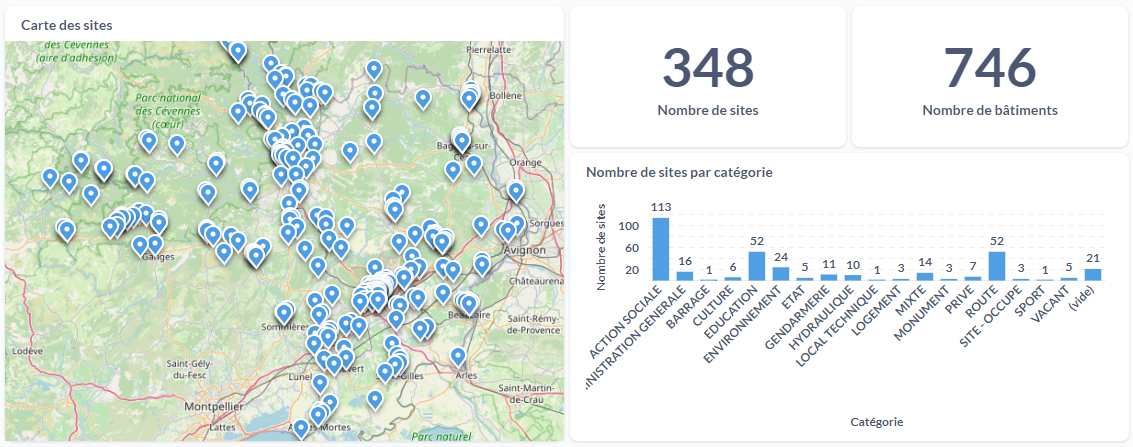
Il est possible, comme spécifié plus haut, de filtrer nos données par catégorie, nom et autres.

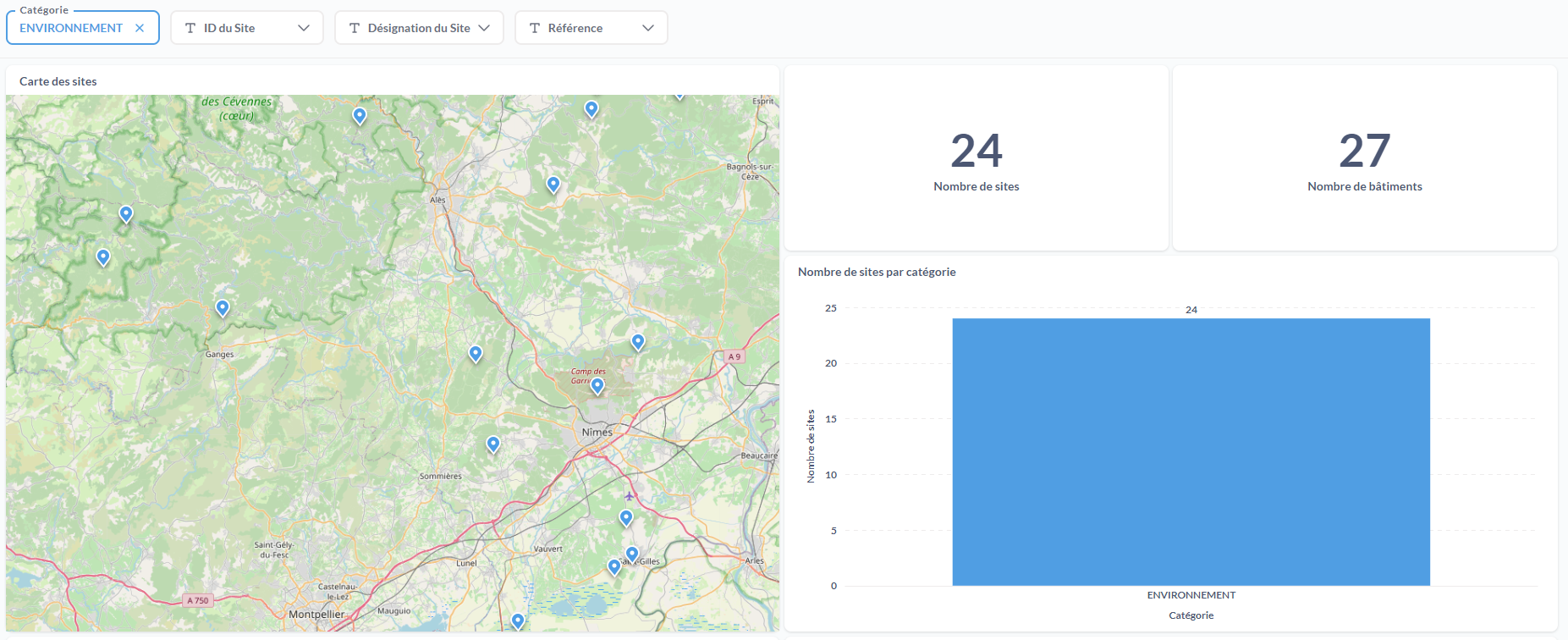
Et voici le résultat lorsqu'on active le filtre sur la catégorie "ENVIRONNEMENT".
En résumé#
Si tu as bien suivi, tu as sans doute compris que nous avions un outil pour chacune des étapes pour respecter la modularité d'une MDS.

Quelques ressources#
Tu pourras trouver le lien vers le support que Michaël a présenté lors des GeoDataDays de Nantes les 19 et 20 septembre 2024. Il explique la Modern Data Stack et détaille le cas d'usage Metabase que je t'ai présenté plus haut.
Modern GIS Stack - Geodatadays 2024
Dans ce replay de la Forward Data Conference, il présente comment la composante géographique a été prise en compte dans Taradata.
Auteur·ice#
Satya MINGUEZ#
En 2023, j'intègre le département du Gard en tant qu'apprenti développeur de la donnée. C'est là que je commence à me familiariser avec le monde de la géomatique en travaillant notamment avec QGIS et PostGIS, l'extension géographique de PostgreSQL.
Licence #
Ce contenu est sous licence Creative Commons International 4.0 BY, avec attribution et partage dans les mêmes conditions.
Les médias d'illustration sont potentiellement soumis à d'autres conditions d'utilisation.
Réutiliser, citer l'article
Vous êtes autorisé(e) à :
- Partager : copier, distribuer et communiquer le matériel par tous moyens et sous tous formats pour toute utilisation, y compris commerciale
- Adapter : remixer, transformer et créer à partir du matériel pour toute utilisation, y compris commerciale.
L'Offrant ne peut retirer les autorisations concédées par la licence tant que vous appliquez les termes de cette licence.
Citer cet article :
"L'enjeu de la data au département du Gard" publié par Satya MINGUEZ sur Geotribu - Source : https://geotribu.fr/articles/2025/2025-02-25_stack_data_gard/
Commentaires
Une version minimale de la syntaxe markdown est acceptée pour la mise en forme des commentaires.
Propulsé par Isso.
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


