Travailler avec du JSON dans PostgreSQL#
 Date de publication initiale : 21 janvier 2025
Date de publication initiale : 21 janvier 2025

Dans le cadre d'un projet personnel, j'ai voulu stocker une bonne partie des données du recensement de l'Insee dans une base PostgreSQL avec des tables multimillésimes. Problème, au sein d'un même jeu de données, les champs peuvent changer au cours des années et cela empêche de pouvoir dégager une structure de table fixe, ce qui est assez gênant vous en conviendrez. La solution ? Passer par des données semi-structurées, soit stocker ces données en JSON dans le champ d'une table. Cet article se veut un condensé de cette expérience.
Obsolescence non programmée
Ces travaux ont été réalisés avant la sortie de PostgreSQL 17 qui ajoute d'importantes fonctionnalités pour le JSON avec les JSON_TABLE, elles ne seront pas évoquées ici.
Puisque nous allons parler de JSON et de données semi-structurées, je me sens dans l'obligation de commencer cet article par un avertissement.
Le modèle relationnel, c'est bon, mangez-en, et les contraintes d'intégrités ont été inventées pour de bonnes raisons.
Cet article ne se veut surtout pas être une invitation à partir en mode YOLO sur la gestion des données "c'est bon ya qu'a tout mettre en JSON" (comme un vulgaire dev qui mettrait tout dans MongoDB diraient les mauvaises langues).
Le JSON pour les débutant⸱es#
Pour celles et ceux qui ne connaissent pas le JSON il s'agit d'un format textuel de représentation des données venant du JavaScript fonctionnant en partie sur un système de clé : valeur qu'on peut voir comme une sorte d'évolution du XML.
Pas besoin de guillemets pour les nombres :
Les valeurs peuvent prendre deux formes :
- soit une valeur unique comme dans l'exemple ci-dessus,
- soit un
array, une liste, qu'on place entre[], les deux pouvant êtres combinés au sein d'un seul objet JSON.
Ce qu'on appelle un objet, c'est tout ce qu'il se trouve entre les {} qui servent à déclarer le dit objet. Pour complexifier tout ça, on peut imbriquer les objets et ainsi vous donner un exemple un peu plus parlant que de parler de tomates et de champignons :
Exemple issu du site de Mozilla qui vous permettra d'approfondir. Vous pouvez aussi consulter l'article wikipedia ou encore l'infâme site de la spécification.
Les types json de PostgreSQL#
PostgreSQL est capable de stocker les données/objets au format json dans des champs auxquels on attribuera un type dédié. Il y en a deux car sinon ça ne serait pas rigolo.
-
Le type
jsonqui est là pour des raisons historiques et laisser fonctionner des bases qui auraient utilisé ce type dans le passé. Il stocke les informations sous forme textuelle, ce qui est peu optimisé pour un ordinateur. Il existe toutefois un intérêt à l'utiliser : il permet de retrouver l'information sur l'ordre des clés. S'il est important pour vous de savoir quenomest la clef 1 etprenomla clef 2, sans avoir à repasser par le nom de la clef, alors il vous faudra passer par le typejson. -
le type
jsonb. Le type moderne. Il stocke les informations sous forme binaire et énormément de fonctions sont disponibles en plus de celles du typejson.
Les index#

Il est possible d'indexer un champ de type json / jsonb sur ses clés de premier niveau et cela se fait avec des index de type GIN :
Pour indexer des valeurs plus "profondes", il faudra passer par des indexs fonctionnels, index sur des fonctions :
CREATE INDEX idx_tb_champjson ON tb USING gin (champ_json -> cle_ou_se_situent_les_valeur_a_indexer);
On expliquera ce -> par la suite.
Pour les aventuriers et aventurières, il existe une extension de PostgreSQL btree_gin permettant de faire des index multi-champs mixant des champs classiques et json. Elle est disponible nativement à l'installation de PostgreSQL et ne vous demandera pas de devenir développeur⸱se C/C++ pour l'installer (coucou les FDW parquet ! Ça va par chez vous ?).
Création des tables#
Je vais éviter de vous spammer du DDL (Data Definition Language, mais vous pourrez retrouver le schéma complet de la base ici.
En voici cependant un schéma succinct pour aider à la compréhension du reste de l'article :
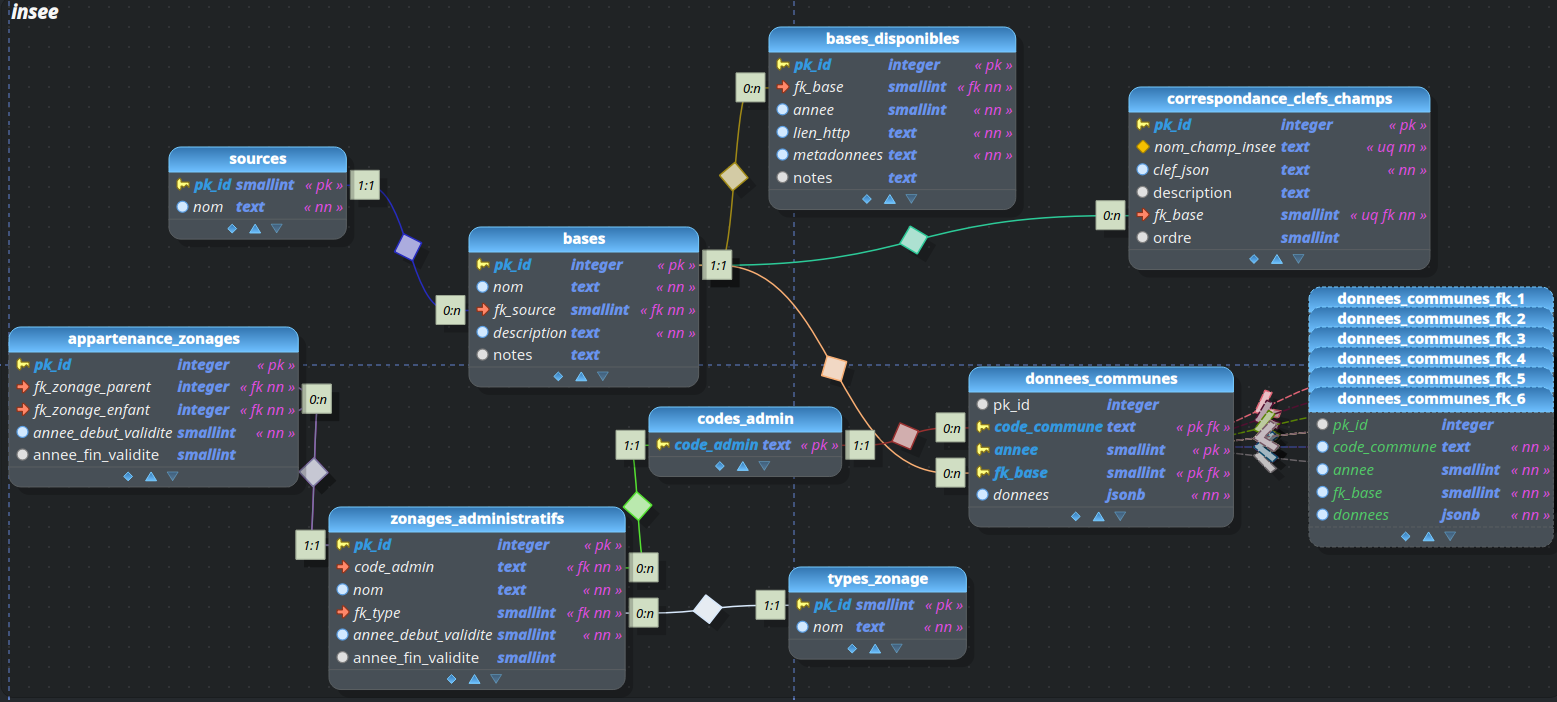
Ne vous préoccupez pas des tables empilées tout à droite, ce sont des partitions de la table donnees_communes. Le sujet ne sera pas évoqué ici et elles ne sont nécessaires pour l'exemple.
Partant d'un schéma nommé insee, on va créer deux tables :
- la première contiendra la liste des bases disponibles, les différents volets du recensement ;
- lae seconde permettant de stocker les données.
Pour rester concentré sur le JSON, on va s'épargner 95% du modèle sous-jacent. On ne gérera donc pas ici les codes communes, etc. :
Les plus tatillons des DBA d'entre vous auront remarqué ce CHECK. "Mais pourquoi qu'il utilise pas varchar(5) ? Il fait vraiment n'importe quoi !" Tout simplement, car cette forme permet d'utiliser un type de texte aux nombres de caractère réellement arbitraire (le type text) contrairement à varchar(255), tout en pouvant en contrôler le nombre minimum et maximum avec le prédicat CHECK (contrairement à varchar qui ne contrôle que le maximum) comme expliqué sur le wiki Postgres.
Et on insère quelques lignes dans notre table insee.bases :
| Script SQL d'insertion de données | |
|---|---|
Insertion de données et récupération#
Pour passer des données textuelles / SQL vers des données encodées en JSON dans le champ dédié qui va bien, PostgreSQL dispose de quelques fonctions. Nous allons utiliser la fonction jsonb_object() qui permet de transformer un array sql sous forme clef1, valeur1, clef2, valeur2 .... en objet jsonb qui n'aura qu'un niveau d'imbrication. D'autres fonctions sont disponibles pour des objets plus complexes (comme jsonb_build_object()).
Exemple simple#
On va créer une chaine de texte qui contiendra le contenu de notre json dont les valeurs seront séparées par des virgules clé1, valeur1, clé2, valeur2. Cette chaine sera passée dans une fonction string_to_array() la transformant en array avec comme séparateur des , pour séparer les éléments de la chaine de texte vers des éléments de liste, caractère passé en second paramètre de la fonction. Cet array sera ensuite envoyé dans la fonction jsonb_object().
INSERT INTO insee.donnees_communes (code_commune, annee, fk_base, donnees) VALUES
(
'99999',
2024,
1,
jsonb_object(
string_to_array('tomates,42,melons,12',',')
)
)
Cette requête encodera cet objet json dans le champs données :
Maintenant comment récupérer notre nombre de melons pour le code commune 99999 en 2024 ? Celà se fait grace à des opérateurs spéciaux :
champ_jsonb -> 'clé'récupère la valeur d'une clé en conservant son type jsonchamp_jsonb ->> 'clé'fait de même en transformant la valeur en type sql "classique"
SELECT
(donnees ->> 'melons')::int4 AS nb_melons
FROM insee.donnees_communes
WHERE
donnees ? 'melons'
AND code_commune = '99999'
AND annee = 2024
Vous pouvez voir que j'utilise l'opérateur ?; uniquement valable pour les champs jsonb et non ceux en simple json. En effet, lorsque l'on requête un champ json/jsonb, un retour vous est fait pour l'ensemble des enregistrements de la table, même ceux ne contenant pas la clé. Comprendre que si votre table contient 100 000 enregistrements, mais que seuls 100 contiennent la clé "melons", ne pas spécifier cette clause WHERE vous renverrait 100 000 lignes, dont 99 900 de NULL.? est un opérateur json permettant de poser la question "la clé est-elle présente au premier niveau du champ json pour cet enregistrement ?", et on ne récupérerait que nos 100 enregistrements contenant la clé "melons".
Je précise que même si vous êtes encore ici, je suppose que vous savez déjà cela. Cependant, la forme (quelque_chose)::(type) est un raccourci de PostgreSQL pour faire un cast soit convertir une valeur dans un autre type. Avec ->> la valeur nous est renvoyée sous forme de texte et nous la convertissons en entier.
Avec du JSON imbriqué#
Bon, il est bien gentil, mais là son JSON reste du JSON où tout est au premier niveau. Bah oui, pour mon besoin, cela m'a suffi. Mais, je ne vais pas fuir mes responsabilités et on va voir comment cela se passe avec du JSON plus complexe.
Je repartirai de l'exemple de la partie précédente pour complexifier après cet aparté.
Pour injecter du json complexe dans un champ, deux solutions s'offrent à nous : imbriquer les fonctions dédiées, ou caster une chaine de texte. Imaginons une table "test", dans un schema "test" et dont un champ jsonb se nomme "donnees".
INSERT INTO test.test (donnees) VALUES
(jsonb_object(
'cle1', 'valeur1',
'cle2', jsonb_array(
'foo', 'bar', 'baz')
)
)
Cette insertion pourrait tout aussi bien s'écrire avec un cast d'une chaine de texte vers du jsonb. Attention, la syntaxe json doit être ici respectée :
INSERT INTO test.test (donnees) VALUES
('{"cle1": "valeur1", "cle2": ["foo", "bar", "baz"]}'::jsonb)
Recupération#
Pour récupérer une valeur, on utilise la fonction jsonb_path_query() qui possède deux paramètres : le nom du champ contenant les données json, et le json_path vers la valeur à atteindre. Imaginons que nous voulions récupérer la deuxième valeur de la liste contenue dans "cle2" :
Le $ désigne le début du chemin json retourné. Nous faisons suivre ce premier symbole par un point pour passer à l'objet suivant. Puis, par le nom de clé suivant et ainsi de suite jusqu'à la clé recherchée, à laquelle nous collons un [1] pour la 2ᵉ valeur de la liste (les valeurs commencent à 0). Pour plus d'informations sur les json_path, vous pouvez consulter la documentation.
Attaquons nous au recensement#

Bien, maintenant que nous avons essayé d'expliquer tant bien que mal les concepts avec des exemples simples, car il faut bien commencer quelque part, essayons avec quelque chose d'un peu plus volumineux.
Récupérons le dernier millésime du volet population du recensement communal au format csv sur le site de l'Insee (vous voulez les bases des principaux indicateurs). Pour l'exemple, on utilisera le fichier "Evolution et structure de la population". Il faut tout d'abord nettoyer les noms de champ. En effet, l'Insee indique le millésime systématiquement dans ses noms de champ, ce qui fait que ces derniers changent tous les ans pour un même indicateur.
Les noms de champ commencent tous par P ou C, ceci indique exploitation principale (réponses brutes aux questions du recensement) ou exploitation complémentaire (croisement de réponses pour établir un indicateur). Les champs provenant de l'exploitation principale et ceux issus de la complémentaire ne doivent pas être croisés entre eux. Cette information est évidemment à conserver, mais par choix personnel, je préfère la mettre à la fin plutôt qu'au début du nom. On passera ainsi de champs normés comme ceci : P18_POP vers une normalisation de ce type POP_P.
Vous trouverez ici un tableur dont le rôle est de s'occuper de tout ça.
Avant d'insérer les données dans notre table, nous allons passer par une table temporaire afin de rendre les données accessibles dans Postgres. Utiliser COPY de Postgresql serait fastidieux car il faudrait indiquer la centaine de champs que contient le volet population du recensement dans la commande. Et, je n'ai pas honte de dire que j'ai un baobab dans la main à cette idée. Nous sortons donc ce merveilleux logiciel qu'est QGIS. On active les panneaux Explorateur et Explorateur2. On crée une connexion vers la base avec les droits de création, et d'un mouvement gracile du poignet, vous glissez le fichier depuis le panneau Explorateur vers la base Postgres dans l'Explorateur2. Laissez la magie opérer.
Maintenant, préparez-vous pour peut-être un des INSERT les plus bizarres de votre vie (en tout cas, ça l'a été pour moi !). Arf. Je me rends compte que si je voulais bien faire, il faudrait aussi que j'explique les CTE. Mais pour ne pas trop alourdir, je vous laisser cliquer sur le lien.
On va utiliser la CTE pour concaténer le nom que l'on veut donner à nos clés avec les valeurs contenues dans notre table temporaire dans une chaine séparée par des ,. On l'enverra dans une fonction string_to_array() puis dans une fonction jsonb_object(). On en profitera pour au passage, nettoyer toute tabulation ou retour chariot qui pourrait subsister avec une expression régulière grâce à la fonction regex_replace(). (ces caractères se notent \t, \n et \r). Cette dernière fonction prend 3 arguments : la chaine de caractères source, le pattern recherché, le texte de remplacement. On y ajoute le drapeau optionnel g afin de remplacer toutes les occurrences trouvées.
Notez que si votre table temporaire possède un nom différent de "rp_population_import" il vous faudra modifier la clause FROM de la CTE.
| L'INSERT le plus bizarre de votre vie (avec une CTE) | |
|---|---|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 | |
Ouf.
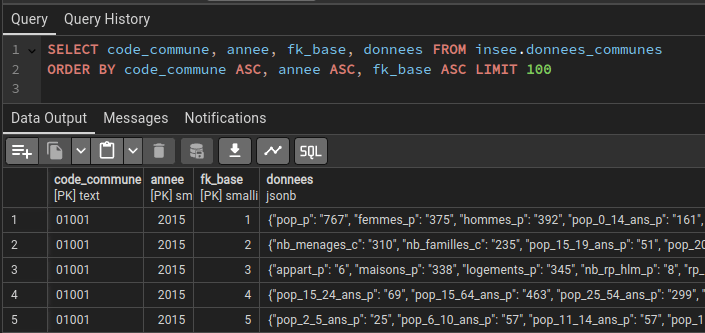
On veillera à bien grouper les inserts dans cet ordre annee/base/code_commune afin de faciliter la lecture des données par PostgreSQL.
Maintenant, imaginez que comme l'auteur de ces lignes, vos gros doigts boudinnés cafouillent et glissent sur les touches lors de la rédaction de cette requête, qu'une faute de frappe s'y glisse, et là c'est le drame. Comment modifier le nom d'une clé déjà encodée dans la table ? Avec cette astuce :
CREATE TABLE example(id int PRIMARY KEY, champ jsonb);
INSERT INTO example VALUES
(1, '{"nme": "test"}'),
(2, '{"nme": "second test"}');
UPDATE example
SET champ = champ - 'nme' || jsonb_build_object('name', champ -> 'nme')
WHERE champ ? 'nme'
returning *;
- est un opérateur qui permet de supprimer une clé d'un objet json. Pour notre UPDATE on enlève donc notre faute de frappe de l'ensemble de l'objet. De plus, on concatène tout le reste avec la construction d'un nouvel objet où l'on corrige le nom de la clé. On assigne également la valeur de la clé en train d'être supprimée, elle est toujours utilisable au moment de l'UPDATE, sur les champs qui la contiennent à l'origine avec ?.
Et maintenant ? Qu'est-ce qu'on fait de ça ?#
Jusqu'à maintenant, nous n'avons travaillé qu'avec le volet population pour son dernier millésime. Imaginons maintenant que nous répétions l'exercice pour les 6 volets et sur plusieurs millésimes, et ce, en sachant qu'au cours du temps, certains champs peuvent apparaitre ou disparaitre ; changement dans les niveaux de diplômes observés par exemple. Il serait intéressant de récupérer une table indiquant la première et la dernière année de présence de chaque clé. Mettons que lors de ces travaux, nous en avons profité pour mettre à jour une table "correspondance_clefs_champs" listant chaque clé présentes et son nom INSEE d'origine (tout du moins, celui que nous avions normalisé).
CREATE MATERIALIZED VIEW insee.presence_clefs_annees AS
SELECT
c.pk_id AS pk_id,
c.clef_json AS clef_json,
c.fk_base AS fk_base,
a.premiere AS premiere_annee_presence,
a.derniere AS derniere_annee_presence
FROM insee.correspondance_clefs_champs AS c,
LATERAL (SELECT
min(annee) AS premiere,
max(annee) AS derniere
FROM insee.donnees_communes WHERE fk_base = c.fk_base AND donnees ? c.clef_json) AS a
ORDER BY fk_base, clef_json;
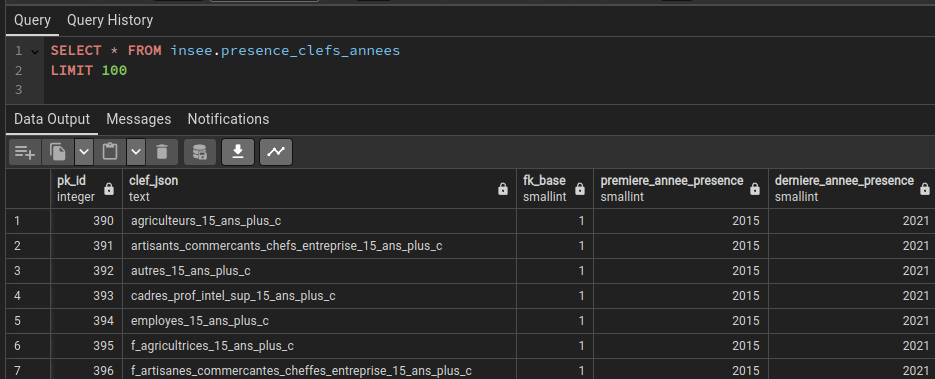
La seule difficulté ici est la présence de LATERAL. Ce « mot » permet d'utiliser un champ de la requête principale dans une sous-requête placée dans une clause FROM. Les éléments de la sous-requête seront ensuite évalués atomiquement avant d'être joints à la table d'origine. Oui, ce n'est pas très facile à expliquer. Ici, le WHERE de la sous-requête va interroger le champ donnees de la table "donnees_communes" pour voir s'il y voit la clef_json en train d'être évaluée dans la table "correspondance_clefs_champs" possédant l'alias "c". Si oui, alors on prend la valeur minimum/maximum du champ année et on le joint à cette ligne et uniquement à cette ligne. Puis évaluation de clef_json suivante ... (évaluée atomiquement)
Maintenant, on voudrait proposer un produit un peu plus simple d'utilisation avec tout ça. Excusez-moi d'avance, je copierai une requête de 50 lignes une seconde fois.
La seule table utilisée ici que nous n'avons pas créée est une table zonages_administratifs comprenant les codes communes dans un champ code_admin et un champ fk_type contenant le type de zonage administratif (1 pour les communes).
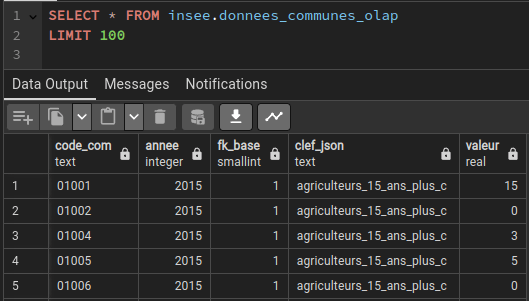
Attention, la création de cette vue matérialisée ou son rafraîchissement peut prendre un certain temps si vous avez stocké beaucoup de données (1 heure chez moi pour les 6 volets de 2015 à 2021).
Enfin, histoire de vivre avec son temps et non comme un vieil ours des cavernes, on va convertir cette vue matérialisée en fichier parquet. Et, pour ça, on va utiliser GDAL qui est décidément incroyable.
ogr2ogr -of parquet donnees_insee.parquet PG:"dbname='insee' schema='insee' tables='donnees_communes_olap' user='nom_utilisateur' password='votre_mot_de_passe'"
Et on peut ainsi mettre le fichier sur un espace cloud, comme ici ! Vous pouvez ensuite sortir votre plus beau générateur de publications Linkedin qui mettra plein d'emojis choupi et faire le cake sur les rezos (imaginez que 90% du contenu de Linkedin doit être fait avec ces trucs qui sont capable de vous générer des publications expliquant que l'un des rares avantages du shape sur le geopackage est d'être un format multi-fichiers, le tout sur un ton très assuré).
Auteur·ice#
Thomas SZCZUREK-GAYANT#

Géomaticien, on a installé un jour QGIS sur mon ordinateur alors que je ne l'avais pas ouvert depuis 2008 et j'ai compris que ma vision de l'open source était dépassée de plus de 10 ans. On peut me retrouver maintenant errant dans les rues en hurlant "passez sous Linux" aux inconnus. Sinon j'aime bien l'astronomie et les chats.
Licence #
Ce contenu est sous licence Creative Commons International 4.0 BY-NC-SA, avec attribution et partage dans les mêmes conditions, sauf dans le cadre d'une utilisation commerciale.
Les médias d'illustration sont potentiellement soumis à d'autres conditions d'utilisation.
Réutiliser, citer l'article
Vous êtes autorisé(e) à :
- Partager : copier, distribuer et communiquer le matériel par tous moyens et sous tous formats
- Adapter : remixer, transformer et créer à partir du matériel pour toute utilisation, exceptée commerciale.
Citer cet article :
"Travailler avec du JSON et PostgreSQL" publié par Thomas SZCZUREK-GAYANT sur Geotribu sous CC BY-NC-SA - Source : https://geotribu.fr/articles/2025/2025-01-21_travailler-avec-JSON-et-PostgreSQL/
Commentaires
Une version minimale de la syntaxe markdown est acceptée pour la mise en forme des commentaires.
Propulsé par Isso.
Ce contenu est sous licence Creative Commons BY-NC-SA 4.0 International 


